Open Access is an initiative that aims to make scientific research freely available to all. To date our community has made over 100 million downloads. It’s based on principles of collaboration, unobstructed discovery, and, most importantly, scientific progression. As PhD students, we found it difficult to access the research we needed, so we decided to create a new Open Access publisher that levels the playing field for scientists across the world. How? By making research easy to access, and puts the academic needs of the researchers before the business interests of publishers.
We are a community of more than 103,000 authors and editors from 3,291 institutions spanning 160 countries, including Nobel Prize winners and some of the world’s most-cited researchers. Publishing on IntechOpen allows authors to earn citations and find new collaborators, meaning more people see your work not only from your own field of study, but from other related fields too.
To purchase hard copies of this book, please contact the representative in India:
CBS Publishers & Distributors Pvt. Ltd.
www.cbspd.com
|
customercare@cbspd.com
While recent object trackers, which employ segmentation methods for bounding box estimation, have achieved significant advancements in tracking accuracy, they are still limited in their ability to accommodate geometric transformations. This limitation results in poor performance over long sequences in aerial object-tracking applications. To mitigate this problem, we propose a novel real-time tracking framework consisting of deformation modules. These modules model geometric variations and appearance changes at different levels for segmentation purposes. Specifically, the proposal deformation module produces a local tracking region by learning a geometric transformation from the previous state. By decomposing the target representation into templates corresponding to parts of the object, the kernel deformation module performs local cross-correlation in a computationally and parameter-efficient manner. Additionally, we introduce a mask deformation module to increase tracking flexibility by choosing the most important correlation kernels adaptively. Our final segmentation tracker achieves state-of-the-art performance on six tracking benchmarks, producing segmentation masks and rotated bounding boxes at over 60 frames per second.
Department of Computer Science and Engineering, New York University, New York, USA
Anthony Tzes
Center for Artificial Intelligence and Robotics, New York University Abu Dhabi, Abu Dhabi, UAE
Electrical Engineering, New York University Abu Dhabi (NYUAD), Abu Dhabi, UAE
*Address all correspondence to: daitao.xing@nyu.edu
1. Introduction
Visual object tracking (VOT) is a fundamental task in various applications, such as robot navigation [1], human-computer interaction [2], and unmanned aerial vehicle (UAV) based monitoring [3]. Given the initial state of an arbitrary target in the first frame, VOT aims to update the location and the states for all the subsequent video frames in real time. Nevertheless, the target object may undergo large appearance changes caused by illumination, deformation, occlusion, and fast motion, which make VOT a very challenging task.
Recent works [4, 5], inspired by the video object segmentation (VOS) task, attempt to obtain a precise target state from the binary per-pixel segmentation mask. A binary segmentation mask provides a much more detailed representation and a closer approximation of the target than a bounding box, especially for elongated and deformable objects. However, methods employing the u-net architecture or pixel-wise binary mask classification are still limited by the model’s geometric transformations, resulting in unstable tracking performance. Among these methods, such as D3S and SATVOS, the focus is on reducing model complexity by utilizing prior knowledge to meet real-time requirements. Nevertheless, the segmentation is performed on the entire search region, which includes distractors. This approach hinders both robustness and speed.
In this research, we propose a novel real-time aerial object tracking framework that utilizes the accuracy of segmentation in a computationally and parameter-efficient manner. Compared to methods such as D3S [5] and SiamMask [4], which predict masks globally or densely, we perform segmentation only on a local tracking region. To achieve this, we introduce a proposal deformation module (PDM) to narrow down the search area to a fixed, small salience patch. Specifically, given the estimated object state from the last frame, the PDM module predicts geometric transformations of the target object by learning an offset from its old position, yielding a coarse updated target state. To better model target geometric variances, we propose a Kernel deformation module (KDM) that disentangles object pose and part deformation from texture and shape for segmentation. A target representation learned from the first frame is decomposed into templates corresponding to different parts of the object. These templates are then applied to the cropped patch from the PDM module in a pixel-wise manner. With a reduced segmentation area, fewer background distractors, and reduced model complexity, our proposed modules achieve higher segmentation accuracy and speed.
To further improve the model’s capability of adaption to the appearance variance and abnormal states like occlusion and truncation, we employ the binary mask from the initial frame and propose a mask deformation module (MDM).
Inspired by Spatial Transformer Networks (STN) [6], an affine transformation function is regressed with a fully connected network conditioned on the current search frame without additional supervision. The transformation is then performed on the initial mask and can include scaling, cropping, and rotations as well as non-rigid deformations. This endows the network with the flexibility of choosing the most important correlation kernels adaptively, resulting in an improvement in model generalization and robustness.
We conducted comprehensive experiments on multiple benchmarks, including six challenging VOT datasets: VOT2016 [7], VOT2018 [8], OTB100 [9], TrackingNet [10], Got10K [11], and LaSOT [12], as well as two VOS datasets: DAVIS16 [13] and DAVIS17 [14]. Superior performance, as well as extensive ablation studies, demonstrate the effectiveness of the proposed method. Particularly, our approach achieves state-of-the-art performance on VOT benchmarks, with an EAO score of 0.485 on VOT2018 [8], while running at over 60 FPS. While our tracker was not originally designed for the VOS task, it still achieves compatible results on both VOS benchmarks.
SiamFC introduces a Siamese architecture, which measures the similarity between the target and search image and trains the network offline. SiamRPN [15] introduces the region proposal network to jointly perform classification and regression in an end-to-end way, DaSiamRPN [16] improves the discrimination power of the model with a distractor-aware module, and SiamRPN++ [17] further improves performance with more powerful deep architectures by overcoming spatial invariance restrictions. Recent works like SiamFC++ [18], Ocean [19], and SiamBAN [20] replace the RPN with an anchor-free mechanism and achieve faster tracking speed. Siamese network-based trackers rely on the first frame to learn a robust target appearance representation without adaptation, which is unreliable during long-term tracking. In contrast to Siamese-based approaches, recent works like DiMP [21] and ATOM [22] learn a discriminative classifier online to distinguish the target from the background. However, the adaptation exists only for classification, while the bounding box estimation still relies on a fixed template matching strategy.
2.2 Video object segmentation
Most recent works [23, 24, 25, 26] resort to large deep networks, multi-scale feature fusion, u-net architecture, or fine-tuning techniques, achieving impressive accuracy. However, tracking efficiency is often overlooked, which is crucial for generic object tracking. Inspired by the significant advancements in the visual object tracking task, recent works tend to solve VOS with a correlation mechanism. SiamMask [4] first proposed a unified approach that predicts the bounding box and mask from a correlation feature map simultaneously. SiamRCNN deploys the segmentation by detection paradigm and predicts the mask inside each proposed box. SiamAtt [27] improves the robustness and discriminative representation ability of the correlation feature map by introducing an attention mechanism. It then performs state estimation and segmentation independently on a refined proposed region. D3S [5] removes the bounding box regression branch and performs segmentation based on the classification map and similarity score map, achieving state-of-the-art performance on the VOT2018 [8] benchmark. However, all these works rely on multiple refinement modules made of upsampling layers and skipping connections to increase robustness, which can also hinder tracking efficiency.
2.3 Transformation modeling
Spatial transformer networks (STN) [6] were the first work to improve the translation-invariant feature modeling ability for deep CNNs by learning a transformation affine function from the input image. Instead of performing global affine transformations, Deformable ConvNets [28] learn offsets for each convolution kernel or ROI pooling layer in a dense way, achieving significant performance improvement on complex vision tasks.
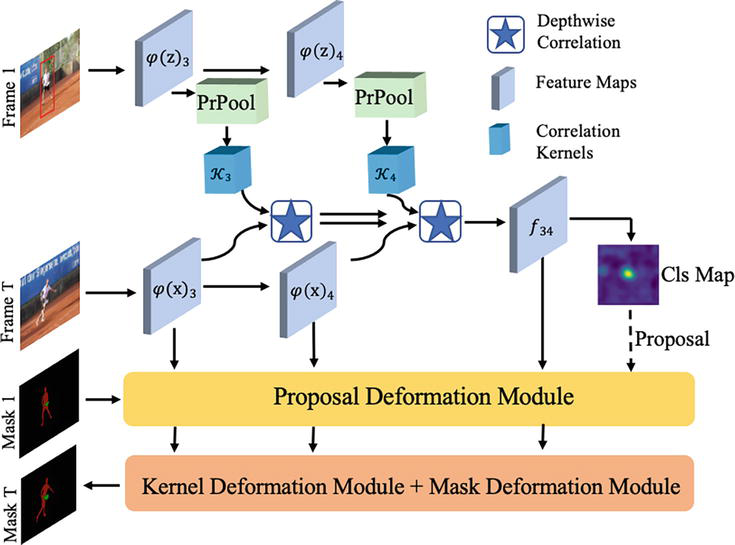
In this section, we describe our tracking framework in detail. The proposed method DCNet consists of four parts: a Siamese-based backbone network for feature extraction presented in Section 3.1, a proposal deformation module (PDM) presented in Section 3.2, a Kernel deformation module (KDM) presented in Section 3.3, and a mask deformation module (MDM) presented in Section 3.4. Figure 1 describes the architecture outline.
Figure 1.
An overview of the proposed tracking framework, consisting of an Siamese-based correlation network, and three deformation modules. The correlation kernels are cropped from different feature blocks, following PrPooling layer.
3.1 Network architecture
Before detailing the proposed modules, we first briefly introduce the backbone network. Similar to a Siamese tracking framework, the proposed framework DCNet consists of two branches: the template branch which takes cropped image z of size w × h from the initial frame as a reference, and the search branch which takes the cropped image x of the same size with z from the current frame for tracking. The two inputs are processed by the same backbone network ψ, yielding two feature maps ψz∈RW×H×C and ψx∈RW×H×C for matching purposes. The reference image also provides the initial target state, represented as a bounding box B0=c0xc0yw0h0. An alternative representation, a binary mask M0∈Rw×h×1 is given in some scenarios but is nonessential.
As in most Siamese-based trackers, cross-correlation is performed between feature maps ψz and ψx. The response score maps representing the similarity between the reference image and the test image are used for target localization and state estimation. We thus retrieve two object-aware correlation kernels K∈R6×6×C from ψz to represent target appearance. Specifically, we crop patches from block3ψz3 and block4ψz4 with the initial state B0 and feed them into a Precise ROI Pooling (PrPool) [29] layer, yielding two fixed-size feature maps K3 and K4. Finally, a depth-wise correlation is performed between K and ψx to generate a target-aware feature representation f3,4∈RW×H×C. Following SiamRPN++ [17], we deploy the multi-layer aggregation strategy by concatenating features f3,4 and feed the joined feature map f34 into a classification module for target localization.
3.2 Proposal deformation module
Compared to D3S [5] and SiamMask [4] which predict masks globally or densely, we only perform prediction on a local tracking region. However, accurate and fast segmentation of a target with appearance changes and deformation requires a proper segment input that encloses the entire target object while precluding the distractors from the background. While the target-aware feature f after correlation can be used to distinguish the target from background distractors, it does not adapt to appearance changes, leading to reduced robustness in localization. To this end, we first propose the proposal deformation module (PDM) to reduce the size of segment input to the ideal area by deforming the region of interest (RoI) from the search area. Unlike the region proposal network (RPN) from mask-RCNN, we make use of the inter-frame consistency of video and generate RoI from the target state in the last frame. Specifically, given the maximum of the correlation response, i.e., ĉtx,ĉty, together with the width and height of the estimated state from the last frame, we generate an initial RoI represented as R=ĉtxĉtyŵt−1ĥt−1.
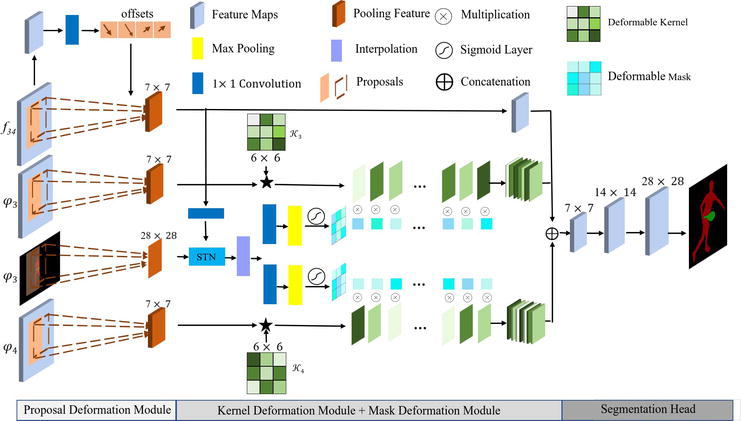
Proposal deformation: As shown in Figure 2, the proposed module refines by R learning a deformation from the initial RoI to the ground-truth state. A PrPool layer is applied on target-aware feature f34, yielding a pooled representation of size K × K × C, where K is the spatial output size of the PrPool layer. From the feature representation, a fully connected layer generates the offsets d, which are then added to the initial RoI R, resulting in a refined RoI R'. We represent the offsets d=lthltwrbhrbw as the distances from R’s left-top corner and right-bottom corner to the corresponding ground-truth ones. Thus, d can be formulated as:
Figure 2.
The proposed deformation modules. The PDM takes the fusion correlation feature and initial proposal as inputs, predicts the offset, and yields a new proposal. The KDM performs part similarity learning (⋆) between the ROI feature and kernel sets from the initial frame. Further, a deformed mask learned from spatial transformation network assigns different scores to the corresponding correlation map adaptively. The final segmentation is inferred from the feature map consisting of local and global correlation maps.
where cty,ctx,ht and wt are from the ground-truth state Bt. Since R provides a good approximation of the target state, the module is lightweight with only a small amount of parameters and computations for the offset learning.
3.3 Kernel deformation module
Given the refined RoI R', a small feature map H of size 7 × 7 is extracted with a PrPool layer from feature maps ψx3,4. Generally, the pooled feature map can be used for instance segmentation in object detection scenarios like MaskRCNN [30]. For the generic object tracking task, however, the object class is nonessential to belong to any set of known categories. Thus, the segmentation introduces misalignment between the target and the instance object, which has a large negative effect on the prediction of masks with pixel accuracy. While cross-correlation can be used to determine interesting parts for segmentation, the cross-correlation methods in [30] lack the ability to model the geometric variance of the target. To this end, we propose a Kernel Deformation Module (KDM) which utilizes part correlation for segmentation purposes.
3.3.1 Part correlation
Formally, given the compact target representation K of size 6 × 6 from ψz3,4 which contains local information (e.g. color, shape) of the target, we first decompose the kernel K into a separate vector kernel set Kii∈0…36. The cross-correlation is performed between H and kernel set Ki which can be formulated as:
C=CiCi=Ki⋆Hi∈0…36E2
where Ci∈R7×7×1 is the response attention map after correlation with kernel Ki. Apparently, kernels that represent distinct local information activate disparate regions on the feature maps. This allows similarity learning which includes object part correlation to find regions of a search image that are most relevant (attention). Finally, we concatenate attention maps set C into a union feature map C'∈R7×7×36.
3.3.2 Segmentation head
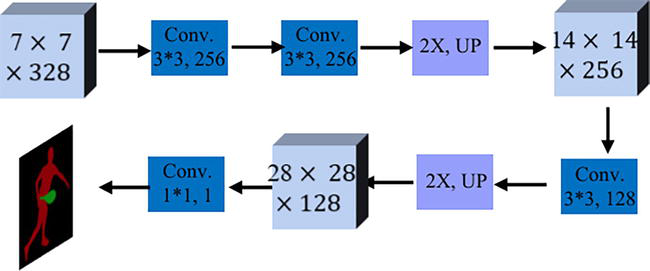
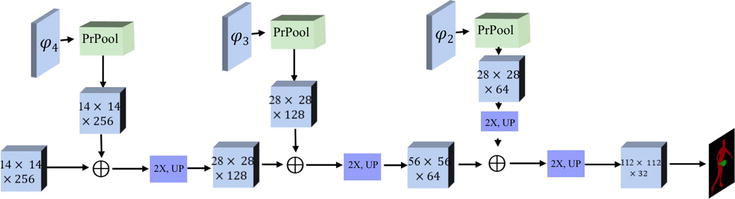
With the aim of producing a more accurate object mask, we merge low and high-resolution features using parallel part-matching branches. As shown in Figure 2, we use both Block3 and Block4 from ψx and generate two pooled feature maps H3,H4, resulting in two correspondent maps C3',C4'. These two attention maps are concatenated before being fed into the segmentation branch. To further improve the discriminative representation ability, we also crop a feature map of size 7 × 7 f34 from and attach it with the attention maps. For the segmentation head, we closely follow the architectures presented in previous work [30]. Specifically, three upsampling blocks consisting of one convolution layer, one activation function, and one deconvolution layer are connected and map the input C3'‖C4' into a predicted mask Mt∈R28×28×1. Figure 3 shows the architecture of the segmentation head. We follow the design from MaskRCNN [30]. Specifically, we use two interpolation layers with convolution layers to up-sample the target into 56∗56 for end-to-end training. During inference, the output mask is resized to the original size. For video segmentation tasks, the pixel-wise segmentation performance is highly related to the size of the segmentation mask. We have since designed a refined module, following the skip connection strategies [4]. As shown in Figure 4, we merge low and high-resolution features by cropping and pooling different blocks (ψ2 to ψ4), and enlarging the size of mask so that the output includes enough details.
Figure 3.
Architecture details of segmentation head.
Figure 4.
Architecture details of refine module.
3.4 Mask deformation module
While the KDM is able to accommodate geometric transformations in object pose, scale, and part deformation, the fixed correlation template strategy without adaptation, hinders the tracking robustness for target appearance variance in the long term, especially in abnormal states like occlusion and truncation. To further improve tracking robustness in harsh cases, we utilize the binary mask from the initial frame M0 and propose a mask deformation module. Specifically, we equip the initial sampling grid from M0∈R28×28×1 with a spatial transformation network T to convert the sampling mask from the initial state to the deformed state. As shown in Figure 2, the transformation function is T obtained from the target-aware map f using a PrPool followed by a fully connected layer. The transformed mask is further encoded with two 3 × 3 convolutional layers, following a max pooling on feature depth to reduce channels into one. The feature map is turned into the desired shape by interpolation, yielding the final encoded mask M̂. While M̂ is a coarse map with limited details provided, the value on each sampling position indicates the importance of the corresponding part from the correlation kernel K. Thus, the part matching could be updated as:
C=CiCi=σmi∗Ki⋆Hi∈0…36E3
where mi is the scalar value from the transformed mask M̂ and σ denotes the sigmoid function which turn mi into a significant score. This endows the network with the flexibility of choosing the most important correlation kernels adaptively. Since both the grid sampling and transformation are differentiable, no supervision is required to learn the transformation parameters θ. In some scenarios such as motion blur or “non-object” instance where a segmentation mask is not provided or unavailable, the mask M0 is filled with ones that gives equal importance to part-matching kernels.
This section describes the implementation details from training to online tracking with the proposed DCNet method.
4.1 Training
Similar to the Siamese-based tracker, the proposed network is trained offline with image pairs. For considerable tracking robustness and speed, we use an ImageNet [31] pre-trained ResNet-50 [32] model as a backbone network. We use the same training split as ATOM [22], i.e., LaSOT [12], TrackingNet [10], and COCO [33] datasets. We also include YouTube-VOS [34] for segmentation training purposes. Like SiamRPN [15], we sample image pairs from the videos with a maximum gap of 50 frames and augment the image dataset (e.g., COCO) with random transformation to generate synthetic image pairs. From a reference image, we sample a square patch centered at the target, with an area of 52 times the target size. For the test image, we sample a similar patch, with some perturbation in the position and scale. Both patches are resized to a fixed size of 288 × 288. To simulate the tracking scenario, we first generate a region proposal by adding random Gaussian noises to the ground truth bounding box and generating 16 candidate states. The variance of the Gaussian function is sampled randomly from [0.01, 0.05, 0.1, 0.2, 0.3, 0.4].
We set C=256 for feature representation in transformation modules. For the PDM, the spatial output size K of the PrPool layer is set to 7. The fully connected layer in MDM used to learn the transformation parameters has a weight matrix filled with zeros and a bias equal to [1, 0, 0, 0, 1, 0].
4.2 Mask representation
In contrast to segmentation methods [5] in the style of FCN [35], which predicts a mask on the entire search area, our approach restricts the segmentation inside the RoI area for inference speed improvement. Apparently, there is an estimation bias of the RoI proposal before and after refinement in PDM, which may impede the training process, resulting in an upper bound of the segmentation head. To address this problem, we expand the proposal size by manipulating a factor γ to the width and height of RoI. To prevent overfitting when learning the segmentation scale changes, we uniformly sample a factor between 1.2 and 1.5 during training. For the inference stage , is fixed to 1.4 for all scenarios. we argue that this process will not introduce additional computation since the RoI is pooled into fixed size, but stabilizes the training process and improves the performance.
Unlike the VOS task, the initial mask is not provided in the VOT dataset. Besides, some scenarios cannot provide a valid semantic mask, which disturbs the segmentation process during inference. We thus fill the initial mask with ones given a probability for the training stage. For inference, an estimated binary mask is predicted using GrabCut [36] in case the mask is not provided. If the estimation fails for abnormal cases, a mask of the same size with the bounding box, filled with ones will be used in MDM.
4.3 Training objective
Both PDM and KDM require supervision during training. We use the Smooth L1 loss for offset learning in Eq. 1 and Binary Cross Entropy (BCE) loss for both binary mask generation and target localization. The total loss of DCNet is:
L=λ1Lcls±λ2Lreg+λ3LmaskE4
where λ1,2,3 are weights for balancing losses and λ1=λ2=λ3=1. Since the initial RoI proposals have a relatively high IoU score between each other, it is unnecessary to predict masks for each RoI proposal. During training, a random proposal is chosen to train the segmentation module. For inference, instead, we use the default proposal without augmentation. The network is trained for 40 epoches with 32 image pairs per batch, giving a total training time of less than 1 day on four GPU TITAN X servers. We use ADAM [37] optimizer with an initial learning rate of 10−3, and decay of the learning rate with a factor of 0.9 every epoch.
4.4 Box generation
We consider the same strategy as [4] to generate a bounding box from a mask. Specifically, a mask from the segmentation branch is converted to a binary mask with a threshold of 0.5. Then, the rotated minimum bounding rectangle (MBR) is applied to yield a rotated bounding box. The segmentation may fail in some abnormal states where the target loses the semantics and cannot be discriminated from the background. We thus measure the IoU score between the bounding box estimation from the segmentation branch with the refined RoI proposal and use the RoI value as the final prediction if the IoU score is less than 0.5. Thanks to the efficiency and robustness of the proposed modules, no additional post-processing steps are required to get the final prediction, yielding a fast inference speed of over 60 FPS on an Nvidia 2060 GPU.
In this section, we compare our approach with the state-of-the-art (sota) methods in two related tasks: VOS and VOT. We first evaluate DCNet on six challenging tracking benchmarks: VOT2016 [7], VOT2018 [8], OTB100 [9], TrackingNet [10], Got10K [11], and LaSOT [12] in Section 5.1. To extensively evaluate the proposed method, we compare it with 21 state-of-the-art trackers. There are 4 anchor-based Siamese framework based methods (SiamRPN [15], SiamRPN++ [17], DaSiamRPN [16] and UpdateNet [38]),4 anchor-free Siamese framework based methods (SiamFC [39], SiamFC++ [18], SiamBAN [20] and Ocean [19]),7 discriminative correlation filter based methods (ECO [40], CSRDCF [41], CCOT [42], ASRCF [43], ROAM [44], DiMP [21], and ATOM [22]), 2 attention based methods (SiamAttn [27], CGACD [45]), 1 multi-domain method (MDNet [46]) and 3 tracking by segmentation methods (D3S [5], SiamMask [4] and SiamRCNN [47]). We then perform an analysis of the segmentation capabilities of DCNet on two popular VOS benchmarks: DAVIS2016 [13] and DAVIS2017 [14] in Section 5.2. Finally, an ablation study is performed based on the VOT2018 [8] dataset in Section 5.3.
5.1 Evaluation on VOT benchmarks
VOT2016 [7] and VOT2018 [8] VOT datasets each consist of 60 sequences with different challenging factors in which targets are annotated by rotated rectangles. VOT benchmarks use the protocol [7] in which the tracker is reset upon tracking failure. Therefore, the tracking results are more comprehensive and insightful. The performance is compared in terms of accuracy (average overlap over successfully tracked frames), robustness (failure rate), and the EAO (expected average overlap), which is a principled combination of the former two measures.
In the VOT2016 dataset, we compare DCNet with the following sota trackers which cover most of the current representative methods: two segmentation-based trackers D3S [5], SiamMask [4], Siamese network-based trackers DaSiamRPN [16], SiamRPN [15], discriminative correlation filter based methods ROAM [44], ASRCF [43], and CSRDCF [41].
Results are reported in Table 1, DCNet outperforms all top-performance sota by a large margin especially in EAO measurement, achieving approximately a 6% boost in EAO compared to the D3S and almost 20% boost in EAO compared to the SiamMask. The accuracy inference comes from two aspects: (1) the segmentation is performed on the RoI proposal instead of the entire search area which may cause truncation if the RoI is not precise enough. (2) The output of segmentation is limited to 28 × 28 for best speed and accuracy trade-off. Nevertheless, the efficiency of the proposed transformation module brings both robustness and speed to the tracker, resulting in an overall boost in performance. Compared with D3S which runs only at 25 FPS, our approach doubles the inference speed, achieving 62 FPS with a significant accuracy increase.
VOT2016 [7] – Comparison with state-of-the-art trackers.
Table 2 shows the performance results on the VOT2018 [8] dataset. DCNet still achieves sota performance in all measures, compared with the recent top-performer D3S. Our method achieves an EAO score of 0.485, a relative 25% improvement compared with SiamMask. Furthermore, DCNet achieves a top robustness score of 0.145 and outperforms the most recent sota discriminative correlation filter DiMP [21] and ATOM [22], demonstrating the robustness of our state transformation module.
VOT2018 [8] – Comparison with state-of-the-art trackers.
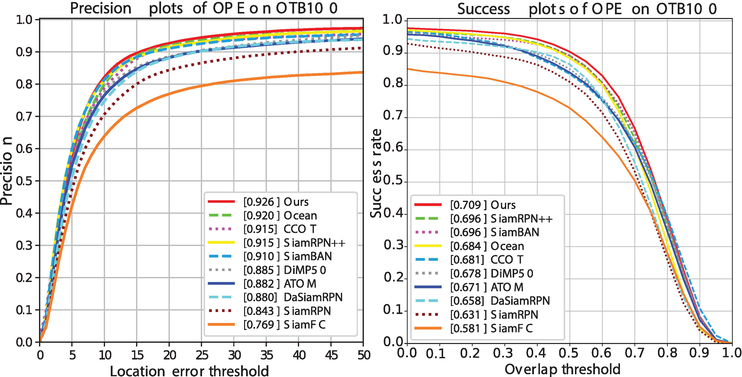
OTB100 [9] The OTB100 [9] dataset contains 100 fully annotated video sequences with substantial variations. We adopt the straightforward One-Pass Evaluation (OPE) as the performance evaluation method. For the performance evaluation metrics, we use precision plots and success plots. Following the protocol in the OTB benchmark, we use the threshold of 20 pixels and Area Under Curve (AUC) to present and compare the representative precision plots and success plots of trackers, respectively. Figure 5 shows the success and precision plots on OTB100. DCNet achieves a similar AUC score compared with top performer SiamRPN++ [17] and outperforms all other sota methods SiamPRN++ [17]. Specifically, our DCNet surpasses ATOM, which is the top discriminative tracker using the same online classification module for target localization, by 4.5 and 4.8% on the success and precision plots respectively, demonstrating the effectiveness of refining RoI proposals using the state transformation module. In addition, our DCNet outperforms the very recent anchor-free tracker SiamBAN [20] on the precision plot.
Figure 5.
Evaluation results of trackers on OTB100 [9].
TrackingNet [10] TrackingNet [10] is a large-scale dataset consisting of more than 30 K videos for training and 511 videos for testing. Trackers are ranked in terms of AUC, and precision. As shown in Table 3, DCNet significantly outperforms all sota methods on precision metric. In detail, our DCNet obtains an improvement of 4.4, 7.3, and 1.1% on precision score compared with top-performing trackers D3S, ATOM [22], and DiMP [21], respectively.
Results on the TrackingNet [10] test set in terms of precision and success (AUC).
Got10K [11] Got10K [11] is another large-scale dataset that was proposed recently. Following the requirement of generic object tracking, there is no overlap in object categories between the training set and test set, which is more challenging and requires a tracker with a powerful generalization ability. We follow their protocol and train the network with training split and YouTube-VOS [34] dataset. The results are shown in Table 4. Note that all the results are tested on their online server. Trackers are ranked according to the average overlap and success rates at two overlap thresholds 0.5 SR0.5 and SR0.75 0.75, respectively. We consider the following sota trackers in comparison: D3S [5], ROAM [44], DiMP [21], SiamMask [4], SiamFC++ [18], ATOM [22], and MDNet [46]. DCNet outperforms all sota methods by a large margin in all performance measures, achieving a relative 4% higher performance in average overlap compared with the sota Siamese-based tracker SiamFC++ [18]. It also outperforms the most recent ATOM [22] and D3S [5] by over 3.7% and over 10.9% in average overlap, respectively, demonstrating the powerful capability of generalized object tracking.
State-of-the-art comparison on the GOT-10 k test set in terms of average overlap (AO) and success rates (SR) at overlap thresholds 0.5 and 0.75.
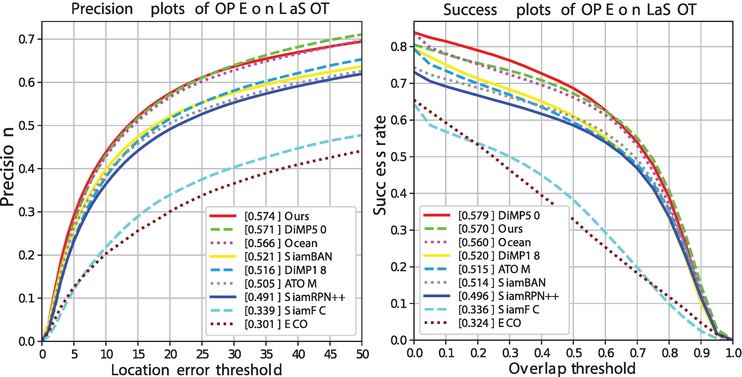
LaSOT [12] LaSOT [12] contains 280 video sequences for testing and employs success and precision plots as measurements. We evaluate our DCNet against the top-performing trackers, including Ocean [19], ATOM [22], DiMP [21], SiamRPN++ [17], SiamFC [39], ECO [40], and SiamBAN [20]. Figure 6 presents the comparison results. Our DCNet achieves sota performance compared with the recent DiMP [21]. Specifically, our DCNet achieves an AUC score of 0.570, with a boost of over 52.8% on performance since MDNet.
Figure 6.
Evaluation results of trackers on LaSOT [12].
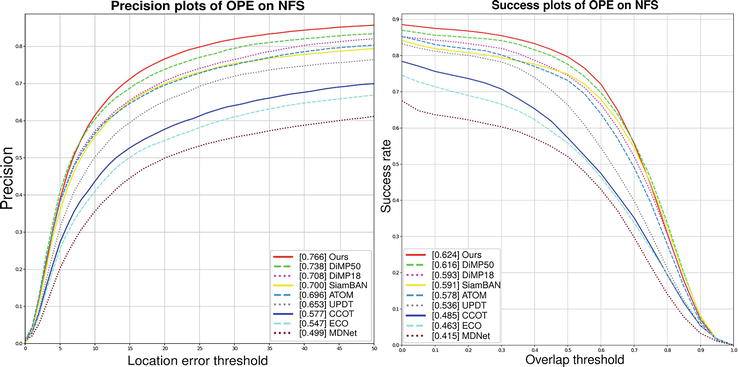
NFS30NFS dataset contains 100 fully annotated video sequences with substantial variations. For the performance evaluation metrics, we use precision plots and success plots. The performance of DCNet is compared with sota trackers including SiamBAN [20], ATOM [22], DiMP [21], UPDT [49], ECO [40], MDNet [46], and CCOT [42]. Figure 7 shows the success and precision plots on NFS30. DCNet outperforms all state-of-the-art trackers under both metrics. Specifically, our DCNet surpasses DIMP-50, which is the top discriminative tracker using the online classification module for target localization, by 4.1% on the precision plots, while achieving a better success rate score, demonstrating the effectiveness of refining RoI proposals using the state deformation module. In addition, our DCNet outperforms the very recent anchor-free tracker SiamBAN [20] on both precision and success plots.
Figure 7.
State-of-the-art comparison on the NFS dataset in terms of precision and success rate.
5.2 Evaluation on VOS benchmarks
For both DAVIS datasets, we use the official performance measures: the Jaccard index J to indicate region similarity and the F-measure F to represent contour accuracy. Following D3S [5], we only report the mean Jaccard index JM and mean F-measure. We compare DCNet with several sota VOS methods including D3S [5], SiamMask [4], OnAVOS [23], FAVOS [24], and OSVOS [25].
For a compact comparison, we designed three variants, i.e. (1) DCNet without mask as input in which case M0 the is filled with (2) The proposed method with both bounding box and mask as input. (3) The proposed method follows with refinement modules as in [5]. Table 5 shows the results of the comparison. DCNet achieves a compatible performance compared with segmentation-based trackers D3S [5] and SiamMask [4]. Compared to D3S [5], the performance of DCNet-w/o mask on DAVIS2016 [13] is only 3 and 9% lower in the mean Jaccard index and mean F-measure respectively, but with speed improvement over 1.5 times. A relatively smaller difference is achieved when providing the tracker with an initial mask. Due to the low resolution (28 × 28) of the segmentation mask, the KDM is prone to giving a lower performance score, especially for the F-measure metric, which expresses the contours similarity. By attaching a refinement module, DCNet outperforms the performance of D3S and SiamMask on DAVIS2016 [13] while reducing the inference speed by over 55%. We thus do not choose to extend the size of the segmentation output. This choice contributes significantly to the efficiency which is crucial for the visual tracking task.
State-of-the-art comparison over the DAVIS2016 and DAVIS2017 VOS benchmarks. Mean Jaccard index and mean F-measure are donated as JM and FM, respectively.
5.3 Ablation analysis
An ablation analysis is performed on the VOT2018 [8] dataset to prove the effectiveness of the different modules of DCNet framework. We establish a baseline by removing all three transformation modules. Specifically, we eliminate the PDM and MDM modules and perform segmentation on the expanded RoI region with the scale factor 0.5 using FCN [35] style, following D3S [5]. The output of the segmentation head has full resolution and same size as the input. The results of the ablation study are presented in Table 6.
PDM
KDM
MDM
EAO
FPS
Baseline
—
—
—
0.397
40
+ PDM
✓
—
—
0.442
38
+ KDM
✓
✓
—
0.477
65
+ MDM
✓
✓
✓
0.484
62
Table 6.
Ablation analysis of DCNet on VOT2018 [8] dataset. We compare the impact of proposal deformation module (PDM), kernel deformation module (KDM), and mask deformation module (MDM).
Effectiveness of PDM. Adding PDM to the baseline model causes an 11.5% performance gain with an ignorable impact on inference speed. This demonstrates the PDM has the capability of locating the most relevant regions of an image in a computationally and parameter-efficient way. Figure 8 shows the state transformation process with RoI proposals before and after refinement.
Figure 8.
Impact of PDM, green and red rectangles are RoIs before and after refinement, respectively.
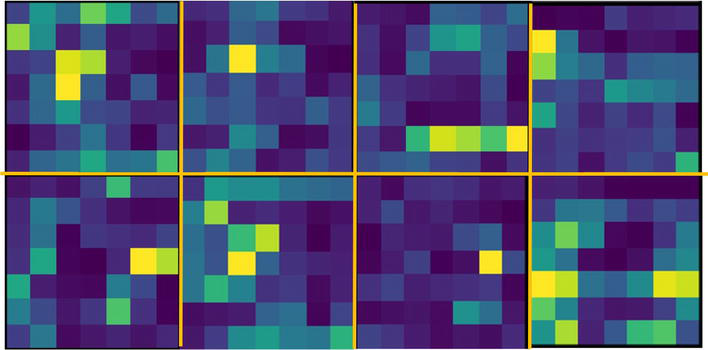
Effectiveness of KDM. The overall tracking performance increased by 7.7% with KDM included to replace the FCN architecture. We argue that the improvement is mainly attributed to two aspects: (1) The FCN [35] relies on skipping connection mechanisms to replenish details, but introduces additional parameters to optimize, causing overfitting problem. We only perform segmentation on a low-resolution patch making the network much easier to converge. (2) FCN deploys a template matching strategy which makes the prediction unstable in abnormal cases over long sequences. Instead, KDM is able to accommodate model geometric transformation by using a part-matching strategy. The attention layers from different part matching are presented in Figure 9.
Figure 9.
Impact of KDM, attention maps from different part matching results.
Effectiveness of MDM. MDM assigns different weights to part kernels in KDM which is helpful in some abnormal cases like occlusion and truncation. While only a small fraction of those extreme cases appear over the whole video sequence, they become pivotal when designing a robust tracking framework, as shown in Figure 10. Overall, MDM brings an extra 1.4% improvement in EAO score with a slight speed drop.
Figure 10.
Segmentation mask and final output: Predicted mask from segmentation branch after interpolation and final output with rotated bounding and mask.
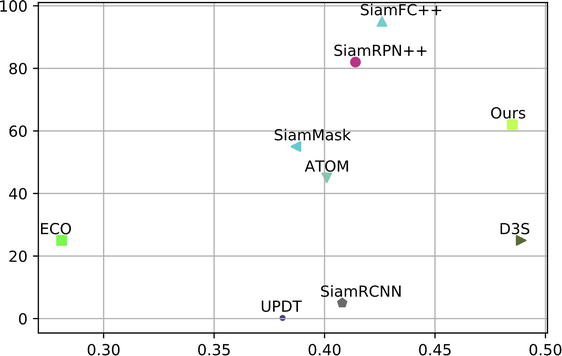
Speed Analysis In Figure 11, we visualize the EAO on VOT2018 with respect to the Frames-Per-Second (FPS). From the plot, our method achieves the best performance, while still running at real-time speed (62 FPS). Figure 10 shows further qualitative results of segmentation branch and bounding box estimation.
Figure 11.
A comparison of the quality and the speed of state-of-the-art tracking methods on VOT2018.
In this work, we propose a deformable correlation network that models geometric transformation from different levels in a highly efficient manner. The comprehensive experiments demonstrate that our approach significantly improves the tracking results, achieving new state-of-the-art performance.
This work was supported by the NYUAD Center for Artificial Intelligence and Robotics (CAIR), funded by Tamkeen under the NYUAD Research Institute Award CG010.
References
1.Lee K-H, Hwang J-N. On-road pedestrian tracking across multiple driving recorders. IEEE Transactions on Multimedia. New York City, United States: IEEE; 2015;17(9):1429-1438
2.Tang S, Andriluka M, Andres B, Schiele B. Multiple people tracking by lifted multicut and person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2017. pp. 3539-3548
3.Mueller M, Smith N, Ghanem B. A benchmark and simulator for uav tracking. In: European Conference on Computer Vision. New York City, United States: Springer; 2016. pp. 445-461
4.Wang Q, Zhang L, Bertinetto L, Hu W, Torr PH. Fast online object tracking and segmentation: A unifying approach. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2019
5.Lukezic A, Matas J, Kristan M. D3s—A discriminative single shot segmentation tracker. In: Proceedings of the IEEE conference on computer vision and pattern recognition. New York City, United States: IEEE; 2020. pp. 7133-7142
6.Tripathi AS, Danelljan M, Van Gool L, Timofte R. Tracking the known and the unknown by leveraging semantic information. In: The British Machine Vision Conference. Vol. 2. Durham, UK: BMVC; 2019. p. 6
7.Čehovin L, Leonardis A, Kristan M. Visual object tracking performance measures revisited. IEEE Transactions on Image Processing. New York City, United States: IEEE; 2016;25(3):1261-1274
8.Kristan M, Leonardis A, Matas J, Felsberg M, Pflugfelder R, Zajc LC, et al. The sixth visual object tracking vot 2018 challenge results. In: Proceedings of the European conference on computer vision workshops. New York City, United States: Springer; 2018. pp. 0-0
9.Wu Y, Lim J, Yang M-H. Online object tracking: A benchmark. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2013. pp. 2411-2418
10.Muller M, Bibi A, Giancola S, Alsubaihi S, Ghanem B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In: Proceedings of the European Conference on Computer Vision (ECCV). New York City, United States: Springer; 2018. pp. 300-317
11.Huang L, Zhao X, Huang K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. In: IEEE Transactions on Pattern Analysis and Machine Intelligence. Vol. 43. no. 5. New York City, United States: Springer; 2019. pp. 1562-1577
12.Fan H, Lin L, Yang F, Chu P, Deng G, Yu S, et al. Lasot: A high-quality benchmark for large-scale single object tracking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2019. pp. 5374-5383
13.Perazzi F, Pont-Tuset J, McWilliams B, Van Gool L, Gross M, Sorkine-Hornung A. A benchmark dataset and evaluation methodology for video object segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2016. pp. 724-732
14.Pont-Tuset J, Perazzi F, Caelles S, Arbeláez P, Sorkine-Hornung A, Van Gool L. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675. 2017
15.Li B, Yan J, Wu W, Zhu Z, Hu X. High performance visual tracking with siamese region proposal network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2018. pp. 8971-8980
16.Zhu Z, Wang Q, Li B, Wu W, Yan J, Hu W. Distractor-aware siamese networks for visual object tracking. In: Proceedings of the European Conference on Computer Vision (ECCV). New York City, United States: Springer; 2018. pp. 101-117
17.Li B, Wu W, Wang Q, Zhang F, Xing J, Yan J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2019. pp. 4282-4291
18.Xu Y, Wang Z, Li Z, Yuan Y, Yu G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In: Association for the Advancement of Artificial Intelligence. Washington DC, United States: AAAI; 2020. pp. 12549-12556
19.Zhang Z, Peng H, Fu J, Li B, Hu W. Ocean: Object-aware anchor-free tracking. In: The IEEE Conference on European Conference on Computer Vision (ECCV). New York City, United States: Springer; 2020. pp. 771-787
20.Chen Z, Zhong B, Li G, Zhang S, Ji R. Siamese box adaptive network for visual tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2020. pp. 6668-6677
21.Bhat G, Danelljan M, Gool LV, Timofte R. Learning discriminative model prediction for tracking. In: Proceedings of the IEEE International Conference on Computer Vision. New York City, United States: IEEE; 2019. pp. 6182-6191
22.Danelljan M, Bhat G, Khan FS, Felsberg M. Atom: Accurate tracking by overlap maximization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2019. pp. 4660-4669
23.Voigtlaender P, Leibe B. Online adaptation of convolutional neural networks for video object segmentation. arXiv preprint arXiv:1706.09364. 2017
24.Cheng J, Tsai Y-H, Hung W-C, Wang S, Yang M-H. Fast and accurate online video object segmentation via tracking parts. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2018. pp. 7415-7424
25.Caelles S, Maninis K-K, Pont-Tuset J, Leal-Taixé L, Cremers D, Van Gool L. One-shot video object segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2017. pp. 221-230
26.Yang L, Wang Y, Xiong X, Yang J, Katsaggelos AK. Efficient video object segmentation via network modulation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2018. pp. 6499-6507
27.Yu Y, Xiong Y, Huang W, Scott MR. Deformable siamese attention networks for visual object tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2020. pp. 6728-6737
28.Dai J, Qi H, Xiong Y, Li Y, Zhang G, Hu H, et al. Deformable convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision. New York City, United States: IEEE; 2017. pp. 764-773
29.Jiang B, Luo R, Mao J, Xiao T, Jiang Y. Acquisition of localization confidence for accurate object detection. In: Proceedings of the European Conference on Computer Vision (ECCV). New York City, United States: Springer; 2018. pp. 784-799
30.He K, Gkioxari G, Dollár P, Girshick R. Mask r-cnn. In: Proceedings of the IEEE International Conference on Computer Vision. New York City, United States: IEEE; 2017. pp. 2961-2969
31.Deng J, Dong W, Socher R, Li L, Li K, Fei-Fei L. Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2009. pp. 248-255
32.He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United States: IEEE; 2016. pp. 770-778
33.Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft coco: Common objects in context. In: European Conference on Computer Vision. New York City, United States: Springer; 2014. pp. 740-755
34.Xu N, Yang L, Fan Y, Yue D, Liang Y, Yang J, et al. Youtube-vos: A large-scale video object segmentation benchmark. arXiv preprint arXiv:1809.03327. 2018
35.Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2015. pp. 3431-3440
36.Tang M, Gorelick L, Veksler O, Boykov Y. Grabcut in one cut. In: Proceedings of the IEEE International Conference on Computer Vision. New York City, United State: IEEE; 2013. pp. 1769-1776
37.Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. 2014
38.Zhang L, Gonzalez-Garcia A, Weijer JVD, Danelljan M, Khan FS. Learning the model update for siamese trackers. In: Proceedings of the IEEE International Conference on Computer Vision. New York City, United State: IEEE; 2019. pp. 4010-4019
39.Bertinetto L, Valmadre J, Henriques JF, Vedaldi A, Torr PH. Fully-convolutional siamese networks for object tracking. In: European Conference on Computer Vision. New York City, United States: Springer; 2016. pp. 850-865
40.Danelljan M, Bhat G, Shahbaz Khan F, Felsberg M. Eco: Efficient convolution operators for tracking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2017. pp. 6638-6646
41.Lukezic A, Vojir T, Zajc LC, Matas J, Kristan M. Discriminative correlation filter with channel and spatial reliability. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2017. pp. 6309-6318
42.Danelljan M, Robinson A, Khan FS, Felsberg M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In: European Conference on Computer Vision. New York City, United States: Springer; 2016. pp. 472-488
43.Dai K, Wang D, Lu H, Sun C, Li J. Visual tracking via adaptive spatially-regularized correlation filters. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2019. pp. 4670-4679
44.Yang T, Xu P, Hu R, Chai H, Chan AB. ROAM: Recurrently optimizing tracking model. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2020
45.Du F, Liu P, Zhao W, Tang X. Correlation-guided attention for corner detection based visual tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2020. pp. 6836-6845
46.Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking. In: Proceedings of the IEEE conference on computer vision and pattern recognition. New York City, United State: IEEE; 2016. pp. 4293-4302
47.Voigtlaender P, Luiten J, Torr PH, Leibe B. Siam r-cnn: Visual tracking by re-detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2020. pp. 6578-6588
48.Danelljan M, Gool LV, Timofte R. Probabilistic regression for visual tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York City, United State: IEEE; 2020. pp. 7183-7192
49.Bhat G, Johnander J, Danelljan M, Shahbaz Khan F, Felsberg M. Unveiling the power of deep tracking. In: Proceedings of the European Conference on Computer Vision (ECCV). New York City, United States: Springer; 2018. pp. 483-498
Written By
Daitao Xing and Anthony Tzes
Submitted: 30 October 2023Reviewed: 01 November 2023Published: 23 January 2024
 Open access peer-reviewed chapter
Open access peer-reviewed chapter