Open Access is an initiative that aims to make scientific research freely available to all. To date our community has made over 100 million downloads. It’s based on principles of collaboration, unobstructed discovery, and, most importantly, scientific progression. As PhD students, we found it difficult to access the research we needed, so we decided to create a new Open Access publisher that levels the playing field for scientists across the world. How? By making research easy to access, and puts the academic needs of the researchers before the business interests of publishers.
We are a community of more than 103,000 authors and editors from 3,291 institutions spanning 160 countries, including Nobel Prize winners and some of the world’s most-cited researchers. Publishing on IntechOpen allows authors to earn citations and find new collaborators, meaning more people see your work not only from your own field of study, but from other related fields too.
To purchase hard copies of this book, please contact the representative in India:
CBS Publishers & Distributors Pvt. Ltd.
www.cbspd.com
|
customercare@cbspd.com
This work illustrates the use of multivariate descriptive statistics methods adapting different dimensional reduction techniques to the analysis of specific data. The particular nature of the data provides an opportunity to illustrate the pedagogical aim of this work. More explicitly, we will analyze and relate two different kinds of information: climate and genetic data and their change over time. We will show that the relation between both types of changes can be attributed to the unveiled genetic changes being compatible with the adaptation of Drosophila subobscura populations to warmer climates. The climate data are the monthly average temperatures of various populations in Europe and America at two different time periods separated by about 25 years. The genetic data include different profiles of Drosophila subobscura chromosomal polymorphisms that, as shown in the scientific literature, are related to the adaptation of the species to different climates. The genetic data have been obtained in the same populations and times as the climate data.
Faculty of Biology, Department of Genetics, Microbiology and Statistics, University of Barcelona, Barcelona, Spain
Lluís Serra
University of Barcelona, Barcelona, Spain
Ferran Reverter
Faculty of Biology, Department of Genetics, Microbiology and Statistics, University of Barcelona, Barcelona, Spain
Josep Maria Oller
Faculty of Biology, Department of Genetics, Microbiology and Statistics, University of Barcelona, Barcelona, Spain
*Address all correspondence to: evegas@ub.edu
1. Introduction
Drosophila subobscura, a small species of fruit fly, has been an object of fascination for geneticists and ecologists due to its remarkable ability to adapt to changing environmental conditions. In recent years, as climate change accelerates and ecosystems undergo changes, researchers have focused their attention in understanding how this species responds to changing climate. It has five pairs of acrocentric chromosomes, all of which exhibit polymorphism for inversions. The frequencies of these chromosome arrangements show a clinal change according to latitude and, therefore, with climate [1, 2]. This particular fly species is native to the Old World and has a wide distribution in its native regions. In February 1978, Drosophila subobscura, which had never before been documented in the Americas, was discovered by chance in southern Chile [3]. The colonization of this species most likely originates from a Mediterranean population, although the precise origin remains undisclosed. A few years later (1982), it was also discovered in North America [4].
To forecast evolutionary responses to natural or anthropogenic perturbations, it is fundamental to determine whether evolutionary trajectories are predictable or idiosyncratic [5]. The predictability of evolution is evaluated by determining whether replicate populations show convergent responses, in particular, by collecting and analyzing genetic and climatological data over time.
Within the field of data analysis, multivariate statistical analysis [6, 7] serves as an indispensable instrument to achieve a deep understanding of data. Specifically, dimension reduction techniques can provide a more complete and holistic view of the data being analyzed. There are a large number of dimension reduction techniques [8, 9], although the principal component analysis (PCA) [9, 10] is the most widely used dimension reduction technique in research. In our case, we will use the power of PCA, matrix algebra operations, and statistics optimization to combine genetic and climatological information at two moments in time. With the aim of obtaining a joint representation that helps interpret whether populations show convergent responses with respect to genetic and climatological data in both Europe and America.
Both population genetics data (from Drosophila subobscura) and climate data will be considered. First, we shall summarize the workflow of the data analysis carried out as follows:
To find a convenient Euclidean space to represent genetic data, starting from a reasonable standard distance between genetic profiles.
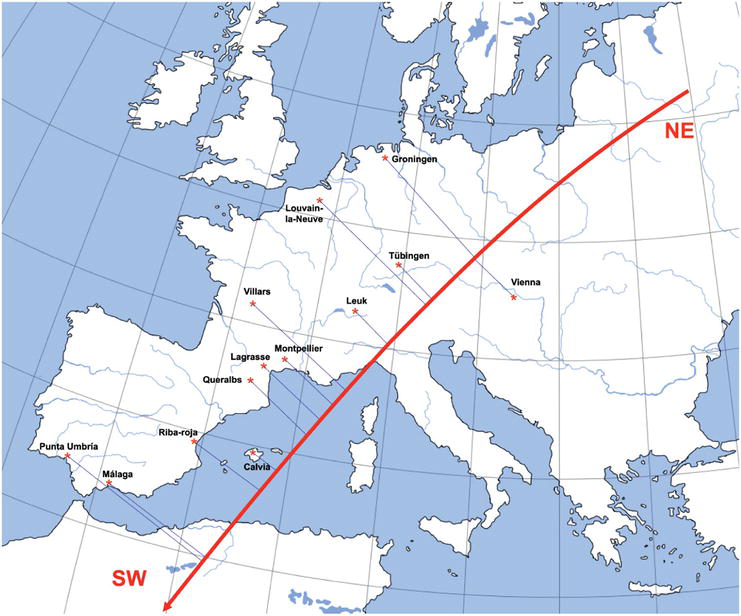
Obtain an interpretable direction in this Euclidean space, in terms of a geographic cline according to the results of a previous paper [11] using only European populations, see Figure 1 and Table 1.
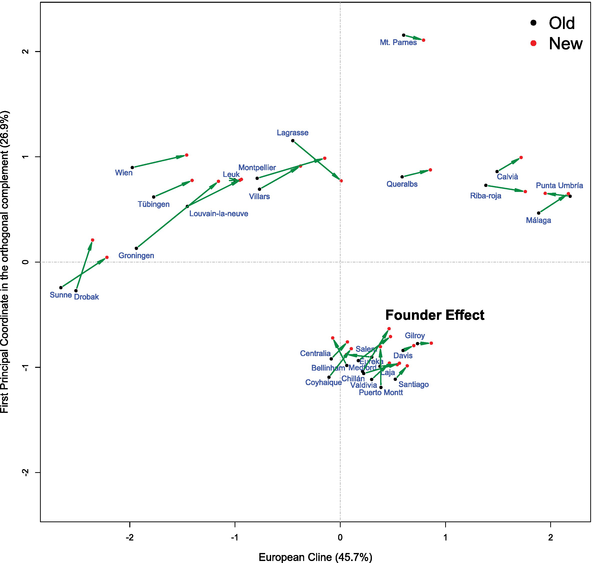
Once this direction has been established, we shall find another direction orthogonal to the first, with all the data, carrying out a standard PCA but onto the orthogonal complement space of the previously mentioned first direction, obtaining a 2D representation (Figure 2). The old and new data from the same geographic population have been represented by two points (one black dot and one red dot, respectively) joined by a time arrow, which visualizes the genetic profile changes.
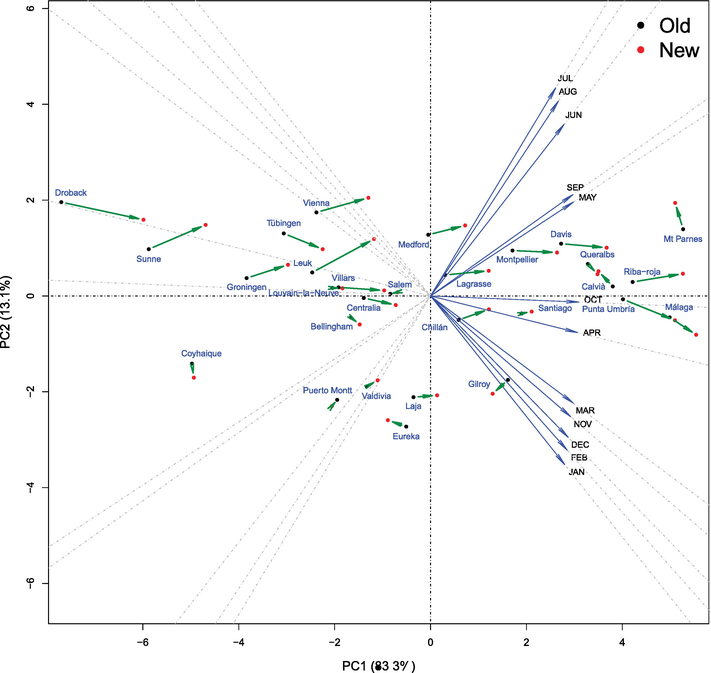
With the climate data, that is, mean month temperatures corresponding to the same populations and periods, we make a PCA BIPLOT analysis, interpreting the first two components as warm weather and extreme (inter-seasonal) weather, obtaining also a 2D representation (Figure 3). The old and new temperature data from the same geographic population are also represented as two points joined by a time arrow, which visualizes the mean temperature changes.
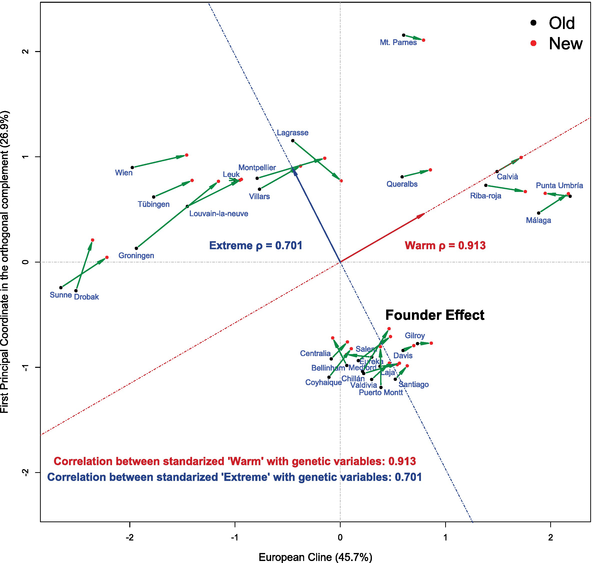
Finally, we integrate both types of information representing the first and second principal components of climate data analysis into the 2D genetic space representation (Figure 4).
Figure 1.
European populations and their relationship with respect to the NE to SW cline. The data can be seen in Table 1.
Population
Longitude/latitude
NE to SW in °
First component
Groningen
53°13′N–6°35′E
0.00°
−1.914748
Wien
48°13′N–16°22′E
0.03°
−1.952958
Louvain-la-neuve
50°43′N–4°37′E
3.20°
−1.429999
Tübingen
48°32′N–9°04′E
3.24°
−1.749663
Leuk
46°19′N–7°39′E
5.85°
−0.981962
Villars
45°26′N–0°44′E
9.93°
−0.743784
Montpellier
43°36′N–3°53′E
10.08°
−0.766615
Lagrasse
43°05′N–2°37′E
11.18°
−0.427634
Queralbs
42°13′N–2°10′E
12.18°
0.611528
Calvià
39°33′N–2°29′E
14.35°
1.513612
Riba-roja
39°33′N–0°34′W
15.96°
1.407313
Málaga
36°43′N–4°25′W
20.37°
1.909295
Punta Umbría
37°10′N–6°57′W
21.54°
2.208420
Table 1.
Longitude and latitude of European geographic populations. Also given are degrees with respect to the NE and SW direction. See also Figure 1. The correlation with the first principal component obtained with the 13 European geographic populations at the first time period is r=0.9628.
Figure 2.
2D representation of the abstract genetic space with the 29 geographic populations studied in two periods. The genetic profile changes are visualized by the arrows. The populations of the old period of time studied are represented with black dots and, in the new period of time, in red dots.
Figure 3.
2D BIPLOT with climate data. The 29 geographic populations are studied in two periods. The temperature changes are visualized by the arrows. The populations of the old period of time studied are represented with black dots, and the new period of time are in red dots. Each one of the variables, mean month standardized temperatures, is represented as blue straight lines whose direction vectors are the gradient of each variable (up to a proportionality constant: Scaled for legibility reasons) and therefore indicates its maximum increase by unit length. The horizontal axis may be interpreted as warm climate (increasing to the right) and extreme interseasonal climate (increasing upward).
Figure 4.
2D dynamic diagram genetic space and climate. Note that changes in the genetic profile are compatible with an adaptation to a warm climate.
2.1 Genetic data
We dispose of data of the chromosomal inversion frequencies corresponding to the five chromosomes of Drosophila subobscura in several European and American populations, each of them sampled in the same geographical places but at two different periods widely separated in the time, 24 years on average. Thus, although we have a total of 29 geographic populations, we shall consider a total of N=29×2=58statistical populations (29 old and 29 new). Let k=5 be the number of chromosomes analyzed (A, J, U, E, and O) and m1,…,mk the number of different chromosomal arrangements located on chromosome A, J, U, E, and O, respectively. Then, given a statistical population Pα, we denote by pαi1…pαimi a vector whose components are the relative frequencies of each chromosomal arrangement located on the i chromosome at population Pα, with pαij≥0 where ∑j=1mipαij=1 with i=1,…,k and α=1,…,N. Further details on the data may be found in [11, 12].
Thus, each geographic population at a given time is characterized as point P in a Genetic Space, P, a point determined by
P=p11…p1m1p21…p2m2…pk1…pkmkE1
From a mathematical point of view, this space is a manifold with boundary of dimension n=∑i=1kmi−k, with coordinate system defined through (1). In the present study, ∑i=1kmi=50, and n=45.
If we consider a discrete multivariate Bernoulli distribution corresponding to each chromosome and we assume independence between them, it is well known that the Fisher information matrix induces a Riemannian structure [13] in the considered manifold that represents the genetic space whose distance will be given in terms of the square root of the sum of squares of the information metric between multivariate Bernoulli distribution corresponding to each chromosome, these being equal to the Bhattacharyya distance, up to at most a multiplicative factor, that is, the distance between two points Pα and Pβ of coordinates determined by pα11…pαkmk and pβ11…pβkmk, respectively, will be
dPαPβ=2∑i=1karccos∑j=1mipαijpβij2α,β=1,…,NE2
Although we do not know the exact coordinates of each statistical population, we have available reasonable estimations of them that, for the sake of simplicity, we shall denote in the same way pα11…pαkmk and pβ11…pβkmk, respectively.
Therefore, from (2), we can obtain a N×N square matrix D=dPαPβ, whose entries are the estimated distances between all pairs of the N=58 studied statistical populations. This distance, up to a multiplicative factor, was already used in [11], with a subset of the data analyzed in the present paper corresponding to 13 geographic European populations in two different time periods (NE=13×2=26 statistical populations).
From this distance matrix, we can carry out a principal coordinate analysis (PCoA) [14, 15]. Specifically, if we let 1N be a N×1 vector whose entries are all equal to 1, IN the N×N identity matrix H=IN−1N1N1Nt, where the symbol t indicates the transpose vector or matrix, the N×N centering matrix A=12D∘D, where ∘ denotes the Hadamard product, we can obtain a spectral decomposition in matrix form A=QΛQt where Λ is a N×N diagonal matrix with the ordered eigenvalues of Aλ1≥λ2≥,…,≥λN and Q is a N×N ortonormal matrix with the corresponding normalized eigenvectors. The eigenvalues obtained range from λ1=84.86376 to λN=−0.2118237, being strictly positive the 38 first eigenvalues. Furthermore, ∑i=138λi=176.8488, whereas ∑i=3958λi=−0.5911. The positive part is approximately the 99.67% of the addition of the absolute value of all eigenvalues. This fact suggests the possibility to map each one of the N=58 statistical populations into a point in Rq where q=38 with coordinates given by the 38 first principal coordinates. If Q˜ is the N×q matrix with the first 38 columns of Q and Λ˜ is the q×q diagonal matrix of the strictly positive ordered eigenvalues λ1≥…,≥λq>0, the 38 principal coordinates of the statistical populations are the rows of the N×q matrix X given by
X=Q˜Λ˜1/2E3
The ordinary Euclidean distance between the rows of X almost reproduces the original distance given in (2). In other words, if we identify each statistical population Pα, with α=1,…,N as a point that has q=38 Euclidean coordinates xα1…xαq such that the ordinary Euclidean distance among them,
dEPαPβ=∑i=1qxαi−xβi2α,β=1,…,NE4
is very similar to dPαPβ. Moreover, we can build the interdistance Euclidean matrix N×N, DE=dEPαPβ, obtaining the following measures:
this small relative error also indicates that D and DE are almost equal.
All these measures indicate a great similarity between (2) and (4) and suggest using, for simplicity, the representation of the N=58 statistical populations in Rq, with the ordinary Euclidean distance as the abstract genetic space into which we represent all of our statistical populations because their proximity relations using the Euclidean distance (4) are almost the same that the ones obtained with (2) proposed initially. The sum of squares between this distance of all considered point will be
SDE2=∑α=1N∑β=1NdE2PαPβ=2NtrXtHXE8
The next step is to obtain a good two-dimensional Euclidean representation that helps us interpret the observed genetic variability. To achieve this purpose, it is important to maximize the variability explained in the 2D graphic output compared with the total variability in the whole Euclidean space (q=38 dimensions). This could be obtained by performing a simple PCA from the data matrix X [8, 9, 10, 15, 16, 17, 18].
We also look for easily interpretable directions in this abstract Euclidean genetic space. Specifically, we will obtain an interpretable direction of this space that will be used as the first axis of the 2D graphic output, that is to say, we will try to interpret a direction of such space in terms of the northeast-southwest (NE-SW) geographic cline described in [11]. In that paper, this cline was identified as the first component of a principal coordinate analysis realized using (2), up to a proportionality constant, and obtained from the data corresponding with the 13 first European populations considered in the present chapter in the two time periods considered.
To obtain in our abstract genetic space the direction linked with the geographic cline described in [11], we shall find the first principal component obtained from the first 13×2=26 rows of data matrix X, which correspond to the European populations studied in [11]. This component will be linked to the geographic cline because (2) and (4) are very similar. Specifically, let Xε be the 26×38 matrix with the 26 first rows of X, and Xρ be the 32×38 matrix with the remaining rows of X, that is, Xt=XεtXρt. The direction searched will be given by the first principal component obtained from Xε. To obtain a PCA with these data, with the same basic notation as before, if we let 1ε be a r×1 vector whose entries are all equal to 1, with r=26, Iε the r×r identity matrix, and Hε=Iε−1r1ε1εt where the symbol t indicates the transpose vector or matrix, the r×r centering matrix, we can build the covariance matrix corresponding to the abstract data matrix Xε, a 38×38 matrix given by Sε=XεtHεXε/r. Then, we will diagonalize this matrix; and because we have r=26 points in an Euclidean space, there will be a maximum of 25 strictly positive covariance matrix eigenvalues, λε1≥λε2≥…≥λεp>0, obtaining a spectral decomposition whose matrix form may be expressed as Sε=UεDεUεt, where Dε is a diagonal p×p matrix with the obtained ordered positive eigenvalues, and Uε is a q×p matrix whose columns are normalized eigenvector corresponding to the aforementioned positive eigenvalues. The first principal component, given by the first column of Uε, referred hereafter simply as the 38×1 column vector u, it will be the direction in the abstract q-dimensional genetic space linked with the geographic cline. This direction summarizes the 100λε1/trSε=69.3% variability of the statistical populations corresponding to European populations. The correlation between the first component obtained and the first principal coordinate analysis described in [11] corresponding to the old data is −0.999999, which indicates the same direction. The negative sign is simply due to the fact that we choose the sign of the first component obtained to be positively correlated with the geographic cline oriented from the NE to SW, see Table 1.
To clearly show the relationship between the first component and the northeast to southwest geographic cline, we can correlate a measurement in degrees along the NE to SW cline, say NE/SW, from 0.00° of Groningen to 21.54° of Punta Umbría, obtained through the standard latitude and longitude coordinates of the different populations, with the values of the first principal component of each geographic population at the old time period studied, say Yεold, obtaining a correlation ρNE/SWYεold=0.9628, see Table 1.
Next, to obtain the second direction of the abstract genetic space that we will use to obtain the 2D representation, we will project all 58 points that represent each statistical population onto the orthogonal complement space of the span of u, u⊥. On this 37-dimensional space, we will carry out a standard PCA and will use the first principal component, say the q×1 column vector v, orthogonal to u and unitary, on the projected points on u⊥ as the second direction of the space where we will project all the points, namely, the span of u and v, uv. Specifically, the projection onto u⊥ is realized by means of the product XI−uut, where I is the 38×38 identity matrix; this N×q matrix with the coordinates of the N=58 populations in u⊥ is a centered matrix, and its covariance will be S=I−uutXtXI−uut/N.
Then, we will diagonalize this matrix S and will have a maximum of q=38 strictly positive covariance matrix eigenvalues, λ1≥λ2≥…≥λq≥0, obtaining a spectral decomposition whose matrix form can be expressed as S=VΛVt, where Λ is a diagonal q×q matrix with the obtained ordered positive eigenvalues, and V is a q×q matrix whose columns are normalized orthogonal eigenvector corresponding to the aforementioned eigenvalues. The first principal component will be given by the first column of V, referred hereafter simply as the q×1 column vector v; it will define the direction in the abstract q-dimensional genetic space that we shall use to complete the desired 2D representation. The direction determined by v summarizes the 100λ1/trS=49.2% variability of the statistical populations corresponding to all populations in u⊥. The 2D final plot will be obtained with the projection of the rows of X into the span of u,v, namely, uv. Introducing the q×2 matrix P=uv, that is, a two column matrix whose columns are the column vectors u and v, the coordinates of the N statistical populations will be rows of the N×2 matrix Y=yαj given by
Y=XPE9
We can easily quantify the percentage of variability represented by each one of the 2D-plot axes, computing first the sum of the squared distance between all the points if we project them in the first axis, SDa12 and in the second one SDa22 of the plot, that is
SDai2=∑α=1N∑β=1Nyαi−yβi2withi=1,2E10
and comparing these quantities with the total variability SDE2 given in (8), we obtain the percentages θai given by θai=100×SDai2/SDE2 with i=1,2, which in the present case are equal to θa1=45.5% and θa2=26.8%, thus, the variability explained by both axis θa1+θa2 will be equal to 72.3%. We can see the described 2D representation in Figure 2; the coordinates of the populations are given by the Eq. (9).
To interpret the change of the genetic profile of the 29 geographic populations between the two periods studied, separated in time on average in just over 24 years, it will be convenient to define two 29×1 column vectors Y1 and Y2 that contains the two coordinates of each one of the 29 populations in the plot, the populations located in the same order in both vectors, at the old period Y1 and at the new one Y2. The change of the genetic profiles of each geographic population between periods may be visualized by δ=Y2−Y1, given by the green arrows in Figure 3 from the black points (populations of the old time period) to the red points (populations of the new time period) (Table 2).
Population
δ1
δ2
Population
δ1
δ2
Montpellier
0.642373
0.190589
Lagrasse
0.459498
−0.381803
Queralbs
0.268763
0.066369
Riba-roja
0.374971
−0.059232
Calvià
0.228700
0.134521
Punta Umbría
−0.237194
0.027191
Málaga
0.282278
0.184082
Groningen
0.780543
0.635947
Louvain-la-neuve
0.513534
0.256845
Villars
0.389008
0.219267
Tübingen
0.364991
0.157145
Wien
0.516528
0.118356
Leuk
0.050395
−0.004103
Sunne
0.438114
0.288466
Drobak
0.158006
0.481837
Mt. Parnes
0.189012
−0.047603
Gilroy
0.130422
0.004212
Davis
0.101785
0.046262
Eureka
0.305773
0.228315
Medford
0.251930
0.405888
Salem
−0.241229
0.023833
Centralia
0.153696
0.160464
Bellinham
−0.133972
0.262271
Santiago
0.113615
0.127641
Chillán
0.339739
0.097727
Laja
0.164784
0.015877
Valdivia
0.168553
0.155098
Puerto Montt
−0.005071
0.386463
Coyhaique
0.212375
0.270840
–
–
–
Table 2.
The components of vectors δ=δ1δ2 represent the profile genetic changes in each of the 29 studied geographic populations. Observe that the 29 components of δ1, the first column vector of δ, are positive in 25 of the 29 cases (each one corresponding to a different population). The shift is compatible with profiles more adapted to the climate of SW.
The few negative values in the second column are highlighted in contrast to the majority of the positive values.
Additionally, among the total of 29 geographic populations considered, in 25 of them in the course of the time between the first and the second period of time studied, a displacement occurs, increasing the value of the first variable used for the 2D representation, which is a direction that represents the NE/SW cline. Moreover, this low value is hardly compatible with a random change (in an ordinary bilateral sign test, p−value≊1.0×10−4). Let us also observe the limited dispersion of American populations, as a consequence of the so-called founder effect produced by the recent colonization of Drosophila subobscura to the New World in the late 70s of the last century when this species was accidentally introduced to America. This effect refers to the reduction of genomic variability due to a small group of individuals separating from the original population [12].
2.2 Climate data
Along with the data analysis of chromosomal polymorphisms in Drosophila subobscura, we recorded meteorological data for the 4 years immediately preceding each biological sample from the nearest meteorological station for each population using NASA GISS. (http://data.giss.nasa.gov/gistemp/) and NOAA (http://www.ncdc.noaa.gov/oa/climate/climatedata.html). Then, we calculate the average monthly temperatures during these 4 years, in degrees Celsius, seasonally adjusting them and taking into account the hemisphere of origin. Thus, to each of the statistical populations considered N=58=29×2, we will associate a vector in R12 whose components are precisely the average temperature values per month, using standardized data to make the analysis invariant under linear changes. Then, we perform an ordinary PCA. Specifically, let W=wαj be a 58×12 real matrix whose entries are the month mean values attached to each statistical population determined by the 29 different geographic sites and two periods, from January to December, seasonally adjusted by hemisphere (for instance, January is the real January in the northern hemisphere but July in the southern hemisphere and similar with the other months) and already standardized. Then, with the same basic notation as before, we can compute the corresponding covariance matrix equal to the correlation matrix because the data are standardized, given by RW=WtHW/N. Then, we will diagonalize this matrix and obtain 12 ordered nonnegative eigenvalues λ1≥λ2≥…≥λ12≥0 obtaining a spectral decomposition whose matrix form may be expressed as RW=TΓTt, where Γ is a diagonal 12×12 matrix with the ordered nonnegative eigenvalues, and T is a 12×12 orthogonal matrix whose columns are normalized eigenvector corresponding to the aforementioned nonnegative eigenvalues. Because λ1=10.00127, the first principal component given by the first column of T summarizes the 83.3% of mean temperature variance; whereas since λ2=1.56655, the second principal component, given by the second column of T summarizes the 13.1% of mean temperature variance. Therefore, the two main principal components summarizes the 96.4% of mean temperature total variance. Explicitly, introducing the 12×2 matrix ϒ=t1t2, where t1 and t2 are the first two columns of T and these two components on the N=58 statistical populations will be given by the two columns of the N×2 matrix C=c1c2=cαj with j=1,2 given by
C=WϒE11
Classical PCA BIPLOT of climate data, see Figure 3, where the populations (labeled in blue) and climate variables (arrows in blue) are represented. The coordinates of the populations corresponding to the old temperature measurements appear in black and the coordinates corresponding to the new measurements (taken 4 years later as average) appear in red. It will be convenient to interpret the variables in order to compute the loadings of the principal components to each variable, and these quantities also obtain a standard BIPLOT [19, 20].
The different variables (from January to December) can be represented by different straight lines through the origin. Table 3 can facilitate the interpretation of the principal components. Because the coefficients determining the first principal component are all positive, we can interpret this component as a size-related component. Specifically, associated with higher temperature, let us call warm climate the first component direction. The blue arrows show the displacement of the populations induced by the time interval. We observe that the arrows are mostly aligned with the first component and, consequently, aligned with an increase of mean temperatures: a shift to a Warmer climate. We can interpret the second principal component as a component related to interseasonal extreme weather, since the loadings of the warmer month are positives and negative the loadings of colder months let us call extreme climate the second component direction.
Population/month
January
February
March
April
May
June
Droback old
−7.025
−8.850
−4.050
2.150
7.975
12.800
Málaga new
14.075
14.825
16.075
17.275
19.250
22.000
Vienna new
0.375
1.725
5.550
10.700
16.350
20.025
Eureka old
9.533
8.833
9.867
10.233
12.175
13.625
Population/month
July
August
September
October
November
December
Droback old
16.600
13.950
9.900
4.725
−1.200
−5.175
Málaga new
24.000
24.575
22.175
20.450
17.425
15.300
Vienna new
21.025
21.525
14.825
10.375
6.125
0.100
Eureka old
14.650
15.125
14.175
12.375
10.350
9.625
Table 3.
The mean temperatures in Celsius degrees of four statistical populations in the different month referred to as northern hemisphere seasons, that is, we shift the data corresponding to populations of the southern hemisphere since in that hemisphere the summer period is the winter in the northern hemisphere, among others.
2.3 Climate data into the 2D genetic space representation
We can represent the first and second principal component of the previously mentioned climate data PCA into the 2D graphic obtained using only genetic data.
One way to proceed is to find the linear combination of the genetic variables (Y1,Y2) that have the maximum correlation with the first and second principal components of climate data c1 and c2, that is, find the coefficients αt=α1α2 and βt=β1β2 such that
The direction defined by αt=α1α2 is the linear combination of the abstract genetic variables Y1 and Y2 that fit the most with the first temperature component c1. In a similar way, the direction defined by βt=β1β2 is the linear combination of the abstract genetic variables Y1 and Y2 that best fits with the second temperature component c2.
After some straightforward computation, the sought coefficients α and β that define the previously mentioned directions in the abstract genetic space and that imply unit variance of the vectors Yα and Yβ are given by
and the achieved maximum correlation with c1 and c2 are respectively
ρ1=c1tYYtY−1Ytc1c1tc1andρ2=c2tYYtY−1Ytc2c2tc2E14
In the present example, we obtain ρ1=0.913466 that shows that the direction corresponding to the first component of the PCA in Figure 4 are closely linearly related with warm climate, whereas the value obtained for ρ2=0.700762 shows an important although weaker linear relationship of the direction corresponding to the second principal component in Figure 4, interpreted as extreme climate.
Furthermore, to study the relationship of the variable which represents the Warm climate with the observed shifts of the genetic population profiles of each geographic population at different times, given by δ, the green arrows from the black points (populations of the old time period) to the red points (populations of the new time period), we can compute the scalar product of these vectors δ with the variable Yα. Among the total of 29 geographic populations considered, in 27 (all with the exception of Punta Umbría and Salem) of them this scalar product is positive indicating that the shift is compatible with a genetic adaptation to a warmer climate. Moreover, this low value is hardly compatible with a random change (in an ordinary bilateral sign test, p−value≊1.6×10−6) (Table 4).
Population
δiYα
δiYβ
Population
δiYα
δiYβ
Montpellier
0.601249
−0.121418
Lagrasse
0.191069
−0.548328
Queralbs
0.245389
−0.062709
Riba-roja
0.272323
−0.222716
Calvià
0.244812
0.016150
Punta Umbría
−0.177003
0.131730
Málaga
0.310490
0.036006
Groningen
0.917106
0.212613
Louvain-la-neuve
0.528855
−0.004008
Villars
0.412010
0.018966
Tübingen
0.364161
−0.025477
Wien
0.467364
−0.128710
Leuk
0.038379
−0.026496
Sunne
0.483173
0.058340
Drobak
0.348535
0.357530
Mt. Parnes
0.129084
−0.128070
Gilroy
0.106166
−0.055364
Davis
0.102679
−0.004933
Eureka
0.349669
0.064752
Medford
0.388557
0.247314
Salem
−0.181777
0.130567
Centralia
0.196843
0.073252
Bellinham
0.013925
0.294317
Santiago
0.149672
0.062186
Chillán
0.316573
−0.066951
Laja
0.139006
−0.060550
Valdivia
0.206240
0.061739
Puerto Montt
0.174221
0.346502
Coyhaique
0.294650
0.144961
–
–
–
Table 4.
The second and fifth columns show the scalar product between δi and Yα. Analogously, the third and sixth columns provide the scalar product between δi and Yβ, where Yα is the direction that represents warm climate in the 2D representation of the genetic spaces and Yβ is the direction which represents extreme climate in the 2D representation of the genetic space. Observe that the scalar product between δi and Yα is positive in almost all population, which is compatible with a profile shift to more warm adapted genetic configurations.
The few negative values in the second column are highlighted in contrast to the majority of the positive values.
In this work, we illustrate a procedure that combines dimension reduction for temporal data and the integration of multiple multivariate sources, in our case, genetic data and climate data. We have proposed a formulation to enrich dimension reduction by choosing interpretable directions in the representation space rather than maximizing variability.
Analysis of the genetic data consistently reveals a shift of populations along the European northeast to southwest cline when comparing the two time periods. On the other hand, the analysis of climate data reveals a first component associated with warm climate. At the same time, a shift of populations in the direction of higher temperature is observed when comparing time points. When we integrate the climatic with the genetic information, we have verified that both displacements, corresponding to the populations in the genetic space and the populations in the climate space, respectively, are highly aligned, suggesting that all populations along the cline are evolving toward the adaptation to a warm climate.
We emphasize that the methodology used in this study is very versatile and easily applicable for multivariate data integration in other areas of application.
1.Prevosti A. Chromosomal polymorphism in Drosophila subobscura populations from Barcelona (Spain). Genetics Research. 1964;5(1):27-38
2.Menozzi P, Krimbas CB. The inversion polymorphism of D. Subobscura revisited: Synthetic maps of gene arrangement frequencies and their interpretation. Journal of Evolutionary Biology. 1992;5(4):625-641
3.Ayala FJ, Serra L, Prevosti A. A grand experiment in evolution: The Drosophila subobscura colonization of the Americas. Genome. 1989;31(1):246-255
4.Beckenbach AT, Prevosti A. Colonization of North America by the European species, Drosophila subobscura and D. ambigua. American Midland Naturalist. 1986;115(1):10-18
5.Huey RB, Gilchrist GW, Carlson ML, Berrigan D, Serra L. Rapid evolution of a geographic cline in size in an introduced fly. Science. 2000;287(5451):308-309
7.Izenman AJ. Modern Multivariate Statistical Techniques. Vol. 1. New York: Springer; 2008
8.Nanga S, Bawah A, Acquaye B, Billa M, Baeta F, Odai N, et al. Review of dimension reduction methods. Journal of Data Analysis and Information Processing. 2021;9:189-231. DOI: 10.4236/jdaip.2021.93013 [Accessed: September 12, 2023]
9.Burges CJ. Dimension reduction: A guided tour. Foundations and Trends® in Machine Learning. 2010;2(4):275-365
10.Hotelling H. Analysis of a complex of statistical variables into principal components. Journal of Educational Psychology. 1933;24(6):417-441. DOI: 10.1037/h0071325 [Accessed: September 12, 2023]
11.Balanyà J, Solé E, Oller JM, Sperlich D, Serra L. Long-term changes in the chromosomal inversion polymorphism of Drosophila subobscura. II. European populations. Journal of Zoological Systematics and Evolutionary Research. 2004;42:191-201. DOI: 10.1111/j.1439-0469.2004.00274.x [Accessed: September 12, 2023]
12.Balanyá J, Oller JM, Huey RB, Gilchrist GW, Serra L. Global genetic change tracks global climate warming in Drosophila subobscura. Science. 2006;313(5794):1773-1775. DOI: 10.1126/science.1131002 [Accessed: September 12, 2023]
13.Burbea J, Rao CR. Entropy differential metric, distance and divergence measures in probability spaces: A unified approach. Journal of Multivariate Analysis. 1982;12(4):575-596
14.Gower JC. Some distance properties of latent root and vector methods used in multivariate analysis. Biometrika Trust. 1966;53:325-338. DOI: 10.1093/biomet/53.3-4.325 [Accessed: September 12, 2023]
15.Borg I, Groenen PJ. Modern Multidimensional Scaling: Theory and Applications. New York, US: Springer Science & Business Media; 2005
16.Kruskal JB. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika. 1964;29(1):1-27
17.Karl Pearson FRS. LIII. On lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 1901;2(11):559-572. DOI: 10.1080/14786440109462720 [Accessed: September 12, 2023]
18.Radhakrishna RC. The use and interpretation of principal component analysis in applied research. Sankhyā: The Indian Journal of Statistics, Series A. 1964;26(4):329-358 http://www.jstor.org/stable/25049339 [Accessed: September 12, 2023]
19.Gabriel KR. The Biplot graphic display of matrices with application to principal component analysis. Biometrika. 1971;58:453-467. DOI: 10.1093/biomet/58.3.453 [Accessed: September 24, 2023]
20.Gower, John C, Lubbe SG, Roux NJL. Understanding Biplots. Hoboken, NJ: John Wiley & Sons; 2011
Written By
Esteban Vegas, Lluís Serra, Ferran Reverter and Josep Maria Oller
Submitted: 18 October 2023Reviewed: 19 October 2023Published: 23 November 2023
 Open access peer-reviewed chapter
Open access peer-reviewed chapter