Open Access is an initiative that aims to make scientific research freely available to all. To date our community has made over 100 million downloads. It’s based on principles of collaboration, unobstructed discovery, and, most importantly, scientific progression. As PhD students, we found it difficult to access the research we needed, so we decided to create a new Open Access publisher that levels the playing field for scientists across the world. How? By making research easy to access, and puts the academic needs of the researchers before the business interests of publishers.
We are a community of more than 103,000 authors and editors from 3,291 institutions spanning 160 countries, including Nobel Prize winners and some of the world’s most-cited researchers. Publishing on IntechOpen allows authors to earn citations and find new collaborators, meaning more people see your work not only from your own field of study, but from other related fields too.
To purchase hard copies of this book, please contact the representative in India:
CBS Publishers & Distributors Pvt. Ltd.
www.cbspd.com
|
customercare@cbspd.com
The surge in digital content has fueled the need for automated text classification methods, particularly in news categorization using natural language processing (NLP). This work introduces a Python-based news classification system, focusing on Naive Bayes algorithms for sorting news headlines into predefined categories. Naive Bayes is favored for its simplicity and effectiveness in text classification. Our objective includes exploring the creation of a news classification system and evaluating various Naive Bayes algorithms. The dataset comprises BBC News headlines spanning technology, business, sports, entertainment, and politics. Analyzing category distribution and headline length provided dataset insights. Data preprocessing involved text cleaning, stop word removal, and feature extraction with Count Vectorization to convert text into machine-readable numerical data. Four Naive Bayes variants were evaluated: Gaussian, Multinomial, Complement, and Bernoulli. Performance metrics such as accuracy, precision, recall, and F1 score were employed, and Naive Bayes algorithms were compared to other classifiers like Logistic Regression, Random Forest, Linear Support Vector Classification (SVC), Multi-Layer Perceptron (MLP) Classifier, Decision Trees, and K-Nearest Neighbors. The MLP Classifier achieved the highest accuracy, underscoring its effectiveness, while Multinomial and Complement Naive Bayes proved robust in news classification. Effective data preprocessing played a pivotal role in accurate categorization. This work contributes insights into Naive Bayes algorithm performance in news classification, benefiting NLP and news categorization systems.
Iğdır University, Department of Computer Engineering, Iğdır, Türkiye
Erkan Veziroğlu
Kütahya Dumlupınar University, Department of Computer Engineering, Kütahya, Türkiye
İhsan Ömür Bucak
Iğdır University, Department of Computer Engineering, Iğdır, Türkiye
*Address all correspondence to: mervearg@gmail.com
1. Introduction
The exponential growth of digital content in recent years has led to an enormous amount of information available online. As a result, there is a growing need for efficient and effective methods to automatically classify and categorize textual data. News classification, a fundamental application of natural language processing (NLP), aims to automatically assign news headlines to certain predefined categories based on their content. This task has important practical implications such as content recommendation, information retrieval, and sentiment analysis.
In this research, we present a comprehensive News Classification task implemented using the Python programming language. The focus of this work is on leveraging the power of Naive Bayes algorithms to accurately categorize news headlines into different classes. Naive Bayes, a well-established and widely used machine learning algorithm known for its simplicity and effectiveness in text classification tasks, is chosen as the basis of our research.
The main objective of this work is twofold: first, to explore the intricacies of building a robust News Classification system, and second, to rigorously evaluate the performance of various Naive Bayes algorithms on the task at hand. To achieve this, we use a dataset obtained from the reputable BBC News Corpus [1], which contains news headlines from five different categories: technology, business, sports, entertainment, and politics. Through detailed analysis, we aim to gain valuable insights into the distribution of categories and the characteristics of headlines. We then perform extensive data preprocessing, including data cleaning, stop word removal, and feature extraction using the Count Vectorizer technique [2]. The dataset is split into training and test sets, and the transformed numeric vectors serve as input for training Naive Bayes algorithms [3].
Our research examines four variants of Naive Bayes: Gaussian Naive Bayes, Multinomial Naive Bayes, Complement Naive Bayes, and Bernoulli Naive Bayes [4]. Each algorithm undergoes rigorous training and is thoroughly evaluated on test data using well-known performance metrics such as accuracy, precision, recall, and F1 score [5]. We also extensively compare the performance of Naive Bayes algorithms with other popular machine learning classifiers such as Logistic Regression, Random Forest, Linear SVC, MLP Classifier, Decision Tree, and K-Nearest Neighbors (KNN) [6]. A detailed analysis of the results is performed to distinguish the relative strengths and weaknesses of each algorithm in the context of news classification.
The findings of our work show that all Naive Bayes algorithms exhibit commendable accuracy on news classification tasks, with Multinomial Naive Bayes and Complement Naive Bayes standing out as particularly effective variants. Furthermore, the MLP Classifier emerges as the best-performing machine learning classifier, demonstrating its effectiveness in the field of news categorization.
In conclusion, this academic research highlights the competent application of Naive Bayes algorithms in news classification and underlines the importance of rigorous data preprocessing and careful algorithm selection. The comprehensive results and insights from this research can serve as a valuable resource for researchers and practitioners in the field of natural language processing and contribute to the advancement of efficient news categorization systems.
News classification is an important area of research to explore various approaches and algorithms to effectively categorize news articles. Many studies in this area have examined the effectiveness of various machine learning and deep learning algorithms, such as Naive Bayes, Support Vector Machines (SVM), Random Forest, Logistic Regression, and neural networks.
The Naive Bayes algorithm is widely used in news classification because of its simplicity, efficiency, and effectiveness. In recent years, several works have been conducted to investigate the use of Naive Bayes algorithms in news classification and to improve its performance. In this section, we will review some of the recent works that use Naive Bayes algorithms in news classification.
Rana et al. investigated news classification based on news headlines and discussed the effectiveness of the Naive Bayes algorithm in this task. They analyze various approaches to feature selection, preprocessing, and classification and compare the performance of Naive Bayes with other classification algorithms. The authors concluded that the Naive Bayes algorithm is a simple and effective method for news classification based on news headlines [7].
Shahi and Pant applied Naive Bayes, Support Vector Machines (SVM), and Neural Networks (NN) to classify Nepalese news articles. They used TF-IDF vectorization to convert text data into machine-readable format and compared the performance of the three algorithms. The results show that Naive Bayes outperforms SVM and NN in terms of accuracy and F1-score. The authors suggested that Naive Bayes algorithm is a suitable method for Nepalese news classification [8].
Chy et al. used a Naive Bayes classifier to classify Bangla news articles. They applied a stemmer and stop word removal to preprocess the text data and used TF-IDF vectorization to convert the data into machine-readable format. The authors compared the performance of Naive Bayes with other classification algorithms and found that Naive Bayes achieved the highest accuracy. They suggested that the use of a stemmer and stop word removal can improve classification accuracy [9].
Bracewell et al. applied the Naive Bayes algorithm to classify Japanese and English news articles. They used a combination of category classification and topic discovery to classify the articles and compared the performance of Naive Bayes with other classification algorithms. The results showed that Naive Bayes achieved the highest accuracy and F1 score. The authors suggested that Naive Bayes algorithm is a suitable method for cross-lingual news classification [10].
Albahr and Albahar used a publicly available dataset to evaluate the news detection capabilities of various machine learning classifiers. They used 80% of the data in the training process and the remaining 20% in the testing process. Naive Bayes classification achieved the best results among the others [11].
Sristy and Somayajulu proposed a semi-supervised approach using the Naive Bayes algorithm to classify news articles based on their content. They used a small labeled dataset and a large unlabeled dataset to train the classifier and compared the performance of Naive Bayes with other semi-supervised algorithms. The results showed that Naive Bayes achieved the highest accuracy and F1-score. The authors suggested that semi-supervised approaches can improve the accuracy of news classification with limited labeled data [12].
Granik and Mesyurar present a simple approach for news detection using a naive Bayes classifier. This approach was implemented as a software system and tested on a dataset of Facebook news posts. In the tests, approximately 74% classification accuracy was achieved [13].
Overall, these works demonstrate the versatility and effectiveness of Naive Bayes algorithms in news classification. They provide insights into how classification accuracy can be improved using different approaches for feature selection, preprocessing, and classification. They also suggest that using Naive Bayes with other algorithms or techniques can further improve the accuracy of news classification.
In this section, we outline the research methodology used to conduct the News Classification work and evaluate the performance of Naive Bayes algorithms. The work includes a systematic approach to data collection, data preprocessing, model training, and performance evaluation. In the following, we describe the key steps taken to ensure the rigor and reliability of the research. The methodology steps are shown in Figure 1.
Figure 1.
General operating procedure.
3.1 Data collection
The data for this work are collected from the BBC News Corpus [1] dataset, which contains news headlines from various categories. The dataset contains two main columns: category and text. The category column represents a category to which each news item belongs, whereas the text column contains the actual text of the news item.
The dataset consists of news headlines from five different categories: technology, business, sports, entertainment, and politics. The number of data points available in each category is shown in Table 1.
Category
Number of data
Tech
401
Business
510
Sport
511
Entertainment
386
Politics
417
Total
2225
Table 1.
Distribution of the data set.
This dataset presents a variety of news headlines, allowing for a comprehensive analysis of Naive Bayes algorithms for news classification. The data collection process ensures that the dataset represents a balanced distribution of news headlines in different categories, making it possible to derive reliable and meaningful insights from the work. Figure 2 shows the details of the dataset.
Figure 2.
Data count distributions for each class.
3.2 Data preprocessing
Data preprocessing is a critical step in preparing raw text data for analysis and classification tasks in natural language processing (NLP). In this task, the data preprocessing steps shown in Figure 3 were performed on the news headlines dataset obtained from the BBC News Corpus. The main goal of data preprocessing is to transform the raw text data into a structured format suitable for further analysis using machine learning algorithms.
Figure 3.
Model preprocessing techniques.
3.2.1 Data cleaning
In the data cleaning phase, we first addressed the issue of punctuation and special characters in news headlines. These non-textual elements do not contribute to the overall meaning and context of the text, and can create noise during analysis. Using regular expressions, we effectively removed punctuation and special characters, leaving only the core textual content intact. Some news headlines may contain numeric values, such as dates, statistics, or other numeric data, which are not appropriate for classification purposes. To prevent numeric values from affecting classification models, we removed them from the headlines. This step ensured that the focus remained on textual content only and minimized the impact of irrelevant information.
3.2.2 Stop word remove
Stop words are commonly used words in a language, such as articles (“the,” “a,” and “an”) and other frequent words (“is,” “are,” and “in”). These words do not carry any significant meaning and are usually removed from the text to reduce dimensionality and focus on more informative features. We used a predefined list of stop words specific to the English language for this purpose. Using the selected stop words, we proceeded to extract them from news headlines. This step effectively reduced the number of words in the dataset, simplifying the subsequent analysis and increasing the relevance of the retained words.
3.2.3 Feature extraction
Tokenization is the process of breaking text into individual words or tokens. We performed tokenization to enable further analysis at the word level by breaking news headlines into meaningful units. From the tokenized words, we created a vocabulary of unique words found in news headlines. This lexicon served as a reference for feature extraction and ensured a consistent representation of words across the dataset. For each news headline, we calculated the term frequency that represents the number of occurrences of each word in that headline. This frequency information was required to convert the textual data into numeric vectors, which were then fed into the machine learning algorithms. The term frequency information was used to create a custom matrix wherein each row represents a news headline, and each column corresponds to a unique word in the vocabulary. The values within the matrix indicate the frequency of occurrence of each word in the relevant headline.
3.2.4 Count vectorizer
The Count Vectorizer technique is a basic approach for creating a numeric matrix representation of text data. It creates a vocabulary from tokenized words and assigns a unique integer to each word. Using the vocabulary generated by Count Vectorizer, a document term matrix was created wherein each row represents a news headline, and each column corresponds to a unique word in the vocabulary. The values in the matrix indicate the frequency of occurrence of each word in the relevant headline.
The data preprocessing steps we implemented played a crucial role in improving the quality of the dataset and preparing it for further analysis using machine learning algorithms. By removing noise, standardizing text, correcting errors, and removing missing data, the cleaned dataset provided a solid foundation for accurate and reliable news classification.
3.3 Machine learning algorithms
Machine Learning (ML) can be defined as a field that studies the ability of computer systems to learn from data. ML algorithms perform tasks such as creating models on datasets and using these models to make predictions or identify patterns. The main goal of ML is to make decisions or predictions based on future data by generalizing from data. To make these generalizations, ML algorithms try to capture data features and patterns using datasets. In this work, we implemented various ML classifiers to perform the task of news classification based on preprocessed data. The classifiers used in this work include Naive Bayes algorithms and other popular ML algorithms.
3.3.1 Naive Bayes algorithms
Naive Bayes is a probabilistic classification algorithm that applies the Bayes theorem with the assumption of feature independence given the class. The mathematical process of Naive Bayes can be explained as follows:
3.3.1.1 Bayes theorem
The Bayes theorem is a fundamental concept in probability theory. It states that the posterior probability of a hypothesis (class) given the observed evidence (features) is proportional to the product of the likelihood of the evidence given the hypothesis and the prior probability of the hypothesis:
PCX=PXC∗PC/PXE1
Here, P(C|X) represents the posterior probability of class C given the observed evidence X, P(X|C) is the likelihood of observing evidence X given class C, P(C) is the prior probability of class C, and P(X) is the evidence probability.
3.3.1.2 Independence assumption of features
Naive Bayes assumes that features are conditionally independent given the class. This assumption simplifies the calculation of probabilities by evaluating each feature independently.
3.3.1.3 Class prior probability (P(C))
The class prior probability represents the likelihood of each class occurring in the training data. It is calculated by dividing the frequency of each class by the total number of samples.
3.3.1.4 Likelihood (P(X|C))
Likelihood represents the probability of observing the evidence (features) given a specific class. In Naive Bayes, likelihood is calculated by assuming feature independence and applying probability distributions specific to each feature type (e.g., Gaussian, Multinomial, and Bernoulli).
3.3.1.5 Posterior probability (P(C|X))
Posterior probability represents the probability of an example belonging to a specific class given the observed features. It is calculated using the Bayes theorem.
3.3.1.6 Classification decision
The final classification decision is made by selecting the class with the highest posterior probability as the predicted class for a given example.
The mathematical operations specific to each Naive Bayes variant (e.g., Gaussian Naive Bayes, Multinomial Naive Bayes, and Bernoulli Naive Bayes) involve estimating class prior probabilities, calculating probabilities based on specific probability distributions and applying Bayes’ theorem.
3.3.1.6.1 Gaussian Naive Bayes
It is a Naive Bayes algorithm used to classify data with continuous features. This algorithm assumes that the features are normally distributed and performs probability calculations based on this distribution. The assumption of independence between features is preserved [14].
3.3.1.6.2 Multinomial Naive Bayes
It is a Naive Bayes algorithm used for classifying data with categorical features such as text classification. This algorithm assumes that the features have a multinomial distribution and performs probability calculations based on word frequencies. The assumption of independence between features is preserved [15].
3.3.1.6.3 Complement Naive Bayes
It is a Naive Bayes algorithm that performs well on imbalanced datasets. This algorithm takes the complement of negative examples to compensate for the imbalance between classes. Complement Naive Bayes performs probability calculations by considering class distributions while maintaining the independence assumption between features [16].
3.3.1.6.4 Bernoulli Naive Bayes
It is a Naive Bayes algorithm used to classify data with binary features. This algorithm assumes that the features have a Bernoulli distribution, which represents the presence or absence of features. The independence assumption is maintained, and the probabilities of the features are calculated [17].
3.3.2 Other popular ML algorithms
3.3.2.1 Logistic regression
It is a classification method used to classify samples in a dataset into two or more classes. Using the characteristics of the samples, the logistic regression model estimates the probabilities of belonging to the classes. These predictions are then evaluated on a decision threshold, and the samples are assigned to classes [18].
3.3.2.2 Random forest
It is an ensemble of many decision trees. Each tree is trained with a randomly sampled dataset and used as a decision tree. The random forest makes a classification decision based on the majority vote of these trees. Thus, more stable and accurate results are obtained [19].
3.3.2.3 Linear support vector machine: Linear SVM
It is a classification algorithm used to classify samples in a dataset into two or more classes. By analyzing the features of the samples belonging to the classes, it creates a hyperplane and performs the classification of the points on this plane. Linear SVM works on the principle of maximum marginal separation and tries to provide the largest margin between classes [20].
3.3.2.4 Multilayer perceptron: MLP
It is a classification model based on artificial neural networks. MLP, which has multiple hidden layers, analyzes data features and makes classification decisions using the correlations between nodes or neurons in each layer. MLP is trained and optimized with a back-propagation algorithm [21].
3.3.2.5 Decision tree: DT
It is a tree structure used to classify instances in a dataset into classes. Based on the characteristics of the dataset, decision nodes, and leaf nodes are created, and decisions are made between these nodes. The decision tree reflects a specific hierarchical structure of features and classes and provides a simple, straightforward classification model [18].
3.3.2.6 K-nearest neighbors: KNN
It is a method that considers the k-nearest neighbors to classify an instance in a dataset. Based on the features of the instances, the classes of the k-nearest neighbors are examined to classify an instance, and a class prediction is made based on the majority vote. KNN is a simple and straightforward classification method but can be computationally expensive on large datasets [22].
Performance metrics play a critical role in evaluating the effectiveness of machine learning algorithms and making informed decisions. These metrics are important for tasks, such as evaluating the performance of algorithms, guiding the optimization process, reporting results, identifying errors and biases, establishing reference points, and detecting overfitting. In this work, commonly used metrics that are effective in evaluating and comparing algorithm performances, especially for the classification process, are used. Metrics commonly used in machine learning include accuracy, precision, sensitivity, and F1 score. Accuracy represents the ratio of all predictions to all correct predictions and indicates an overall model performance. Precision refers to the proportion of successful predictions relative to all positive predictions of the model. Sensitivity measures the ratio of all positive samples to correct positive predictions and indicates how many true positive samples the model correctly identifies. The F1 score is the harmonic mean used to strike a balance between precision and sensitivity. All metrics have mathematical formulas given by the following equations:
Accuracy=TP+TNTP+TN+FP+FNE2
Precision=TPTP+FPE3
Recall=TPTP+FNE4
F1−score=2xPrecisionxRecallPrecision+RecallE5
4.2 Results
According to the results given in Table 2, the performance of four different Naive Bayes algorithms, Gaussian Naive Bayes, Multinomial Naive Bayes, Complement Naive Bayes, and Bernoulli Naive Bayes, are compared.
NB algorithms
Accuracy (%)
Precision (%)
Recall (%)
F1 score (%)
Gaussian
92.92
93.08
92.92
92.93
Multinomial
98.20
98.20
98.20
98.20
Complement
98.31
98.31
98.31
98.31
Bernoulli
96.67
97.01
96.74
96.77
Table 2.
Results for Naive Bayes algorithms.
The Complement Naive Bayes algorithm has the highest accuracy of 98.31% and was successful in classifying the dataset in the best way. Multinomial Naive Bayes and Bernoulli Naive Bayes algorithms showed high performance with 98.20% and 96.67% accuracy rates, respectively. The Gaussian Naive Bayes algorithm, on the other hand, achieved a lower success rate compared to the other algorithms with 92.92% accuracy.
All Naive Bayes algorithms showed high success in precision values. This shows that the classification results of the algorithms are accurate and precise. The Complement Naive Bayes algorithm has the highest precision value, with a precision of 98.31%.
All Naive Bayes algorithms showed high success in recall values. This shows the ability of the algorithms to accurately identify true classes in classification. The Multinomial Naive Bayes algorithm has the highest precision value with a recall rate of 98.20%.
The F1 score is a combined measure of precision and sensitivity. All Naive Bayes algorithms have high F1 scores. The Complement Naive Bayes algorithm achieved the highest success with an F1 score of 98.31%.
According to the results given in Table 2, the performance of six different ML algorithms, Logistic Regression, Random Forest, Linear SVC, MLP Classifier, Decision Tree, and KNN, are compared.
The MLP Classifier algorithm has the highest accuracy of 98.31% and was successful in classifying the dataset in the best way. Linear SVC and Random Forest algorithms showed high performance compared to the other algorithms, with 97.97% and 97.86% accuracy rates, respectively. Decision Tree and KNN algorithms performed poorly compared to the other algorithms with lower accuracy values.
All ML algorithms showed high success in precision values. This shows that the classification results of the algorithms are accurate and precise. MLP Classifier algorithm has the highest precision value with a 98.32% precision rate.
All ML algorithms showed high success in recall values. This shows the ability of the algorithms to accurately identify the true classes in classification. The MLP Classifier algorithm has the highest precision value with a recall rate of 98.31%.
The F1 score is a combined measure of precision and sensitivity values. All ML algorithms have high F1 scores. The MLP Classifier algorithm achieved the highest success with an F1 score of 98.31%.
In conclusion, the Complement Naive Bayes algorithm has the highest accuracy, precision, sensitivity, and F1 score, whereas the MLP Classifier algorithm has the highest accuracy, precision, sensitivity, and F1 score. Other algorithms have also shown successful results, but some of them have lower performance.
When the Complement Naive Bayes and MLP Classifier algorithms are analyzed, the Complement Naive Bayes algorithm achieves high success with an accuracy rate of 98.31%. The MLP Classifier algorithm performed at the same level as Complement Naive Bayes with an accuracy rate of 98.31%.
The Complement Naive Bayes algorithm has a precision rate of 98.31%, meaning that the classification results are accurate and precise. The MLP Classifier algorithm has a slightly higher accuracy than Complement Naive Bayes with 98.32% accuracy.
The Complement Naive Bayes algorithm has a precision of 98.31%, indicating its ability to accurately identify true classes. The MLP Classifier algorithm also has a sensitivity of 98.31%, which is on par with Complement Naive Bayes.
The F1 score is a combined measure of precision and sensitivity. Both Complement Naive Bayes and MLP Classifier algorithms have high F1 scores.
According to the analysis results, Complement Naive Bayes and MLP Classifier algorithms show similar performance. Both algorithms have high accuracy, precision, sensitivity, and F1 score values. When making a choice, they can be preferred depending on the characteristics of the dataset and the requirements (Figures 4 and 5).
Figure 4.
Accuracy graph for Naive Bayes algorithms.
Figure 5.
Accuracy graph for ML algorithms.
Comparing the results of Tables 2 and 3, the overall comparison between Naive Bayes and ML algorithms shows that Naive Bayes algorithms (Gaussian, Multinomial, Complement, and Bernoulli) have an average accuracy rate of 97.77%. ML algorithms (Logistic Regression, Random Forest, Linear SVC, MLP Classifier, Decision Tree, and KNN) have an average accuracy of 87.91%. Naive Bayes algorithms show higher accuracy values compared to ML algorithms.
ML algorithms
Accuracy
Precision
Recall
F1 score
Logistic Regression
97.52%
97.52%
97.52%
97.52%
Random Forest
97.86%
97.91%
97.86%
97.87%
Linear SVC
97.97%
97.98%
97.97%
97.98%
MLP Classifier
98.31%
98.32%
98.31%
98.31%
Decision Tree
82.69%
82.84%
82.69%
82.72%
KNN
55.84%
80.88%
55.84%
56.59%
Table 3.
Results for other ML algorithms.
Naive Bayes algorithms have an average accuracy rate of 97.63%. ML algorithms have an average precision of 84.08%. Naive Bayes algorithms show higher precision values compared to ML algorithms.
Naive Bayes algorithms have an average sensitivity rate of 97.79%. ML algorithms have an average sensitivity rate of 83.29%. Naive Bayes algorithms show higher sensitivity values compared to ML algorithms.
Naive Bayes algorithms have an average F1 score of 97.71%. ML algorithms have an average F1 score of 83.16%. Naive Bayes algorithms have higher F1 scores compared to ML algorithms.
As a result, Naive Bayes algorithms (Gaussian, Multinomial, Complement, Bernoulli) generally outperform ML algorithms (Logistic Regression, Random Forest, Linear SVC, MLP Classifier, Decision Tree, and KNN). Naive Bayes algorithms provide high accuracy, precision, sensitivity, and F1 score values in the news classification problem. However, ML algorithms may also have different advantages in the field of machine learning and may be preferred in certain situations.
The confusion matrix provides valuable information about the algorithms’ ability to correctly predict class labels and discriminate between various categories. Based on the Confusion Matrix results of the Naive Bayes algorithms given in Figure 6, we can interpret their performance in classifying news headlines into different categories.
Figure 6.
Confusion matrixes of Naive Bayes algorithms.
The Multinomial Naive Bayes algorithm achieved an overall high accuracy rate of 98.20%. It performed extremely well in the “technology” and “sports” categories, correctly classifying 153 and 194 instances, respectively. However, it made a few misclassifications in the “business” and “entertainment” categories, with only 204 out of 205 instances correctly classified in the “business” category and 157 out of 158 in the “entertainment” category. The algorithm’s precision, recall, and F1 score for each category are consistently high, demonstrating its ability to correctly identify relevant examples while minimizing false positives and false negatives.
The Gaussian Naive Bayes algorithm achieved a lower accuracy of 92.92% compared to Multinomial Naive Bayes. It encountered difficulties in correctly classifying some instances, especially in the “work” and “entertainment” categories. For example, it misclassified 11 instances in the “business” category and 14 instances in the “entertainment” category. While it performed well in the “technology” category, correctly classifying 149 out of 161 examples, it struggled in other categories. The algorithm’s precision, recall, and F1 score are generally lower than those of Multinomial Naive Bayes, indicating a trade-off between precision and recall.
The Complement Naive Bayes algorithm achieved an accuracy of 98.31%, slightly higher than Multinomial Naive Bayes. It performed consistently across all categories and made only a few misclassifications. It achieved excellent accuracy in the “technology” and “business” categories, correctly classifying all instances. It also performed well in the “sports” category, correctly classifying 196 out of 198 instances. The algorithm’s precision, recall, and F1 score were equally high across categories, making it a robust and reliable choice for news classification tasks.
The Bernoulli Naive Bayes algorithm achieved an accuracy of 96.67%, which is lower than Multinomial and Complement Naive Bayes. It faced challenges in the “business” category, misclassifying 11 instances, and in the “entertainment” category, misclassifying four instances. It performed well in the “technology” category, correctly classifying 143 out of 155 instances, while it faced difficulties in the “sports” category, misclassifying nine instances. The algorithm’s precision, recall, and F1 score are generally lower than those of Multinomial and Complementary Naive Bayes, indicating that there is potential room for improvement in its performance.
In summary, Multinomial Naive Bayes and Complement Naive Bayes algorithms performed strongly in classifying news headlines and achieved high accuracy and precision in all categories. The Gaussian Naive Bayes algorithm had some difficulties in discriminating between categories, while the Bernoulli Naive Bayes algorithm performed competitively but faced difficulties in some categories. According to the Confusion Matrix results, Multinomial Naive Bayes and Complement Naive Bayes algorithms seem to be the most suitable choices for accurate and reliable news classification. However, further analysis and finetuning may be required to optimize the performance of each algorithm for specific application requirements.
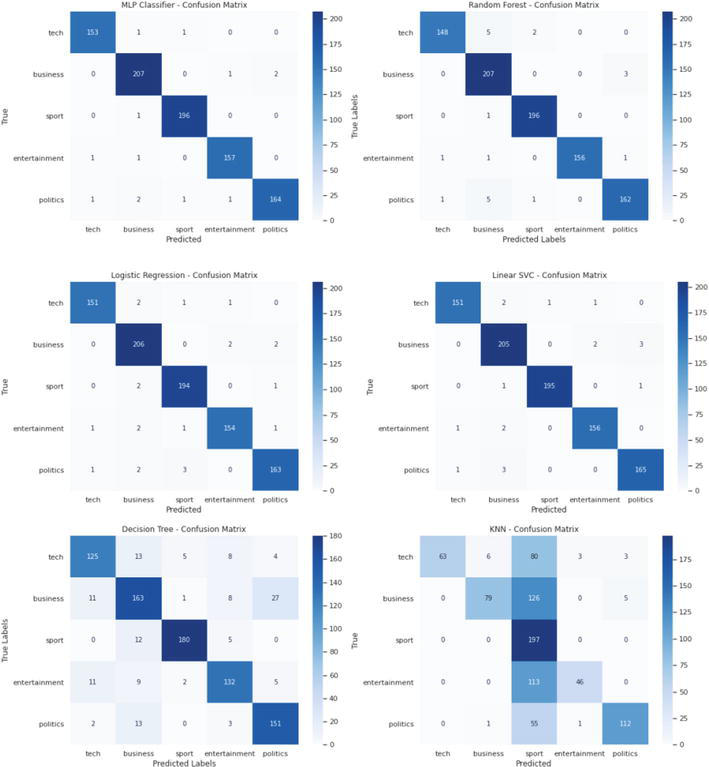
Based on the Confusion Matrix results of the machine learning classifiers given in Figure 7, Logistic Regression achieved a high accuracy rate of 97.52% when we look at their performance in classifying news headlines into different categories. It performed well in most categories, with the highest accuracy in the “technology” category (151 out of 153 correctly classified examples) and the “business” category (206 out of 208 correctly classified examples). However, it encountered difficulties in correctly classifying some instances in the “sports” and “entertainment” categories. The algorithm’s precision, recall, and F1 score for each category are generally high, indicating that the algorithm is able to correctly identify relevant examples while minimizing false positives and false negatives.
Figure 7.
Confusion matrixes of ML algorithms.
Random Forest achieved a slightly higher accuracy of 97.86% compared to Logistic Regression. It performed consistently in most categories, correctly classifying a large number of instances in the “technology,” “business,” and “entertainment” categories. However, it encountered difficulties in the “sports” category, misclassifying five instances. The algorithm’s precision, recall, and F1 score were equally high across categories, making it a robust and reliable choice for news classification tasks.
Linear SVC achieved an accuracy of 97.97%, slightly higher than Random Forest. It performed strongly in most categories, achieving the highest accuracy in the “technology” category (151 out of 154 instances were correctly classified). However, it made a few misclassifications in the “business” and “entertainment” categories. The algorithm’s precision, recall, and F1 score were consistently high across categories, indicating its effectiveness in news classification.
The MLP Classifier achieved an accuracy of 98.31%, the highest among all classifiers. It performed excellently in most categories, with the highest precision achieved in the “technology” category (153 out of 155 instances were correctly classified) and only a few misclassifications in the “business” and “entertainment” categories. The algorithm’s precision, recall, and F1 score were consistently high across categories, making it the optimal choice for accurate and reliable news classification.
The Decision Tree achieved an accuracy of 82.69%, which is lower than other classifiers. It faced difficulties in correctly classifying examples in all categories, with the highest precision achieved in the “technology” category (125 out of 161 examples were correctly classified). The algorithm’s precision, recall, and F1 score are lower than the other classifiers, suggesting a trade-off between precision and recall.
KNN achieved the lowest accuracy of 55.84% among all classifiers. It faced difficulties in correctly classifying instances in all categories, with the highest precision in the “technology” category (63 out of 152 instances were correctly classified). The algorithm’s precision, recall, and F1 score were generally low, suggesting potential room for improvement in its performance.
In summary, the MLP Classifier showed the highest accuracy and precision, making it the most suitable choice for accurate and reliable news classification. Random Forest and Linear SVC also showed strong performance, whereas Decision Tree and KNN had difficulties in discriminating between categories. Classifier selection should take into account the specific context and requirements of the actual research work to achieve optimal and effective news classification results.
In conclusion, the Multinomial Naive Bayes, Complement Naive Bayes, and MLP Classifier algorithms have shown outstanding performance in news classification with accuracy exceeding 98%. Complement Naive Bayes and MLP Classifier emerged as the best-performing algorithms, achieving the highest accuracy, precision, recall, and F1 score. These results highlight the effectiveness of Naive Bayes algorithms and MLP Classifier algorithms in accurately categorizing news headlines, making them viable options for practical applications in content recommendation, information retrieval, and sentiment analysis tasks.
In this work, we investigate using Naive Bayes algorithms for news classification using a dataset of news headlines obtained from the BBC News Corpus. The main goal was to build a competent News Classification system and evaluate the performance of various Naive Bayes variants. Through extensive experiments and analysis, we gained valuable insights into the effectiveness of these algorithms in text classification tasks.
Our research findings demonstrate the robustness and effectiveness of Naive Bayes algorithms in news classification. Multinomial Naive Bayes and Complement Naive Bayes emerged as the best performing variants, showing consistently high accuracy, precision, recall, and F1 score. These results are in line with previous research highlighting the effectiveness of Naive Bayes in handling discrete feature data, which is well suited for text-based classification challenges [16, 23].
We also compared Naive Bayes algorithms with other popular machine learning classifiers, including Logistic Regression, Random Forest, Linear SVC, MLP Classifier, Decision Tree, and KNN. MLP Classifier exhibited the highest accuracy among all classifiers. This finding is in line with the recognized ability of deep learning models to effectively capture complex patterns in textual data [24].
Rigorous data preprocessing played a crucial role in the successful implementation of our News Classification system. By cleaning the text data, eliminating stop words, and extracting informative features, we converted the raw headlines into a numerical format suitable for training classification models. Leveraging the Count Vectorizer technique allowed us to skillfully transform text data into numerical representations, thus facilitating the smooth implementation of machine learning algorithms.
Our research adds significant value to the fields of natural language processing and machine learning by providing critical insights into the performance of Naive Bayes algorithms and their comparative analysis with other classification techniques in the news classification domain. The findings emphasize the importance of using appropriate data preprocessing techniques and selecting the most appropriate algorithm to achieve accurate and reliable news classification.
As a limitation, it is crucial to recognize that our work focuses only on a specific dataset of news headlines obtained from the BBC News Corpus. Future research efforts could investigate the generalizability of these findings on larger and more diverse datasets covering various news sources and different topics.
In conclusion, this work proves the effectiveness of Naive Bayes algorithms in news classification and underlines the potential power of the MLP Classifier as an attractive alternative. The insights gained from this research can provide a solid foundation for the development of efficient and scalable news categorization systems with wide-ranging applications in content recommendation, information retrieval, and sentiment analysis.
References
1.Greene D, Cunningham P. BBC Datasets. 2006. Available from: http://mlg.ucd.ie/datasets/bbc.html
2.Patel A, Meehan K. Fake news detection on reddit utilising count vectorizer and term frequency-inverse document frequency with logistic regression, multinominal NB and support vector machine. In: 2021 32nd Irish Signals and Systems Conference (ISSC). Athlone, Ireland: IEEE; 2021. pp. 1-6
3.Saritas MM, Yasar A. Performance analysis of ANN and Naive Bayes classification algorithm for data classification. International Journal of Intelligent Systems and Applications in Engineering. 2019;7(2):88-91
4.Chen S, Webb GI, Liu L, Ma X. A novel selective naïve Bayes algorithm. Knowledge-Based Systems. 2020;192:105361
5.Powers DM. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv preprint arXiv:2010.16061. 2020
6.Mahesh B. Machine learning algorithms-a review. International Journal of Science and Research (IJSR). 2020;9(1):381-386
7.Rana MI, Khalid S, Akbar MU. News classification based on their headlines: A review. In: 17th IEEE International Multi Topic Conference 2014. Karachi, Pakistan: IEEE; 2014. pp. 211-216
8.Shahi TB, Pant AK. Nepali news classification using Naive Bayes, support vector machines and neural networks. In: 2018 International Conference on Communication Information and Computing Technology (ICCICT). Mumbai, India: IEEE; 2018. pp. 1-5
9.Chy AN, Seddiqui MH, Das S. Bangla news classification using naive Bayes classifier. In: 16th International Conference on Computer and Information Technology. Khulna, Bangladesh: IEEE; 2014. pp. 366-371
10.Bracewell DB, Yan J, Ren F, Kuroiwa S. Category classification and topic discovery of Japanese and English news articles. Electronic Notes in Theoretical Computer Science. 2009;225:51-65
11.Albahr A, Albahar M. An empirical comparison of fake news detection using different machine learning algorithms. International Journal of Advanced Computer Science and Applications. 2020;11(9)
12.Sristy NB, Somayajulu D. Semi-supervised Learning of Naive Bayes Classifier with feature constraints. In: Proceedings of the First International Workshop on Optimization Techniques for Human Language Technology. 2012. pp. 65-78
13.Granik M, Mesyura V. Fake news detection using naive Bayes classifier. In: 2017 IEEE first Ukraine Conference on Electrical and Computer Engineering (UKRCON). IEEE; 2017. pp. 900-903
14.John GH, Langley P. Estimating continuous distributions in Bayesian classifiers. arXiv preprint arXiv:1302.4964. 2013
15.McCallum A, Nigam K. A comparison of event models for naive bayes text classification. In: AAAI-98 Workshop on Learning for Text Categorization. Madison, WI; 1998. pp. 41-48
16.Rennie JD, Shih L, Teevan J, Karger DR. Tackling the poor assumptions of Naive Bayes text classifiers. In: Proceedings of the 20th International Conference on Machine Learning (ICML-03). 2003. pp. 616-623
17.Zhang H. The optimality of naive Bayes. Aa. 2004;1(2):3
18.Hastie T, Tibshirani R, Friedman JH, Friedman JH. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd edn. New York, NY: Springer; 2009
19.Breiman L. Random forests. Machine Learning. 2001;45:5-32
20.Cortes C, Vapnik V. Support-vector networks. Machine Learning. 1995;20:273-297
21.Bishop CM, Nasrabadi NM. Pattern Recognition and Machine Learning. Springer; 2006
22.Cover T, Hart P. Nearest neighbor pattern classification. IEEE Transactions on Information Theory. 1967;13(1):21-27
23.Yang Y, Pedersen JO. A comparative study on feature selection in text categorization. In: ICML. Nashville, TN, USA; 1997. p. 35
24.LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436-444
Written By
Merve Veziroğlu, Erkan Veziroğlu and İhsan Ömür Bucak
Submitted: 10 August 2023Reviewed: 25 August 2023Published: 17 January 2024
 Open access peer-reviewed chapter
Open access peer-reviewed chapter