 Open access peer-reviewed chapter
Open access peer-reviewed chapter
Abstract
The chapter presents the knowledge management system, developed in the context of an interdisciplinary project called TOXIN, for the toxicity testing domain to facilitate the safety assessment of new cosmetic ingredients. Tools have been developed to capture existing knowledge captured in Safety Evaluation Opinions documents issued by the Scientific Committee on Consumer Safety in a knowledge graph, to enrich this knowledge with knowledge from other sources, and to access this knowledge efficiently. Ontologies and semantic technology are used to build the toxicological knowledge graph and its tools. The developed knowledge management system is based on the processes for creating, maintaining, and exploiting knowledge graphs defined in the Abstract Reference Architecture. The chapter discusses the approach followed for developing the knowledge management system, and the tools developed to support the different processes of the Abstract Reference Architecture. These tools include end-user tools, as well as more advanced tools for information technology experts.
Keywords
- knowledge graph construction
- knowledge consumption
- knowledge graph enrichment
- knowledge graph engineering
- data lifting
- quality assurance
- domain ontology development
- end-user development
- toxicity testing
- jigsaw metaphor
1. Introduction
Toxicology is a field of science investigating the potentially harmful effects of chemical compounds on living organisms, including humans. An important branch of toxicology is regulatory toxicology, in which chemical safety assessments are carried out in order to permit decisions towards the protection of health against adverse effects of chemical substances under their conditions of use [1]. Historically, animal testing has formed the basis for chemical safety assessment. Yet, scientific considerations and ethical constraints have driven a worldwide shift towards using animal-free methods for this purpose. This has been enforced by Regulation (EC) NO 1223/2009, imposing a full ban on animal testing in the cosmetics field, but also across other sectors, including pharmaceutical, food, and biocide industries, there is a tendency to address animal-free methods for safety evaluation. This has resulted in efforts to develop animal-free methods for evaluating the safety of chemicals, incorporating cell culturing and computational approaches. In general, there are four main approaches for toxicity testing:
In vivo toxicity testing involves exposing living animals to a substance to observe its effects on their health and behaviour.In vitro toxicity testing involves conducting experiments on cells or tissues taken from a living organism. This method allows for more controlled conditions, as it eliminates the influence of other body systems on the effects of the substance being tested.In silico toxicity testing involves using computer models to simulate the effects of a substance on a living organism and how a living organism interacts with a substance. This method relies on mathematical and statistical models and data fromin vivo andin vitro studies to predict the toxic effects of a substance.In chemico approaches aim to utilise an understanding of chemical reactivity to obtain insights regarding reactivity, aiding in the assessment of toxicity. Numerous experimental methods exist for assessing reactivity, and there is a growing trend of translating this information into computational (in silico ) tools to streamline hazard identification. Whether obtained through experimentation or computation, thein chemico data should be incorporated into a strategic framework to support the decision-making process.
Although
TOXIN is developing a knowledge management system that gathers and organises all available toxicity data described in documents issued by the Scientific Committee on Consumer Safety2 about cosmetic ingredients listed as annexed II, III, IV, V, and VI under Regulation EC No 1223/2009. Each such document, called a Safety Evaluation Opinion, contains information about experiments (also called tests) of a chemical compound on e.g. laboratory animals, including information on the outcome of these tests, as well as the authors’ opinions about the compound’s toxicity. In TOXIN, semantic technology is adopted to build this toxicological knowledge management system. By using semantic technology, the information can be structured flexibly. This is because semantic technology represents and stores information using a graph data model, which is less rigid than the traditional relational model adopted in relational databases. This means that information can be added to entities as needed, avoiding complex data migration. Further, where the schema and data are “tightly coupled” in traditional relational databases, the graph data model in semantic databases is “schemaless”; the “schemas”, which are called ontologies later on, are declared as facts themselves, and one can combine several such ontologies. Semantic technology allows us to express the semantics of the information, provides advanced querying mechanisms, and allows us to integrate diverse data from multiple sources into a coherent and meaningful
In this chapter, we present the approach followed for developing the knowledge management system, as well as the tools developed for it. The different tools support different processes for creating, maintaining, and exploiting knowledge graphs introduced in Ref. [3] by following the Abstract Reference Architecture (ARA). Two tools are provided for defining the knowledge graph of the knowledge management system and filling it with data: an end-user tool, based on the jigsaw metaphor, that allows the manual definition and filling of a knowledge graph by our subject matter experts (i.e. toxicologists), and a tool to automatically import toxicity data previously collected by the toxicologists from Safety Evaluation Opinions in spreadsheets into the knowledge graph. We also discuss integrating multiple other data sources from the field of toxicology into the TOXIN knowledge system to facilitate hazard assessment of new compounds by presenting the relationships integrating the different data sources to the toxicologists. Next, we discuss how we currently tackle aspects of the quality assurance of the knowledge graph. Furthermore, a search and query tool has been developed allowing toxicologists to explore and search in the knowledge graph. We also discuss how integrating the other data sources from the toxicological field can be used to answer questions formulated in the context of toxicity testing.
The chapter is organised as follows: Section 2 presents the background, i.e. introducing the concept of a knowledge graph, as well as the concepts of ontology and vocabulary. Next, the existing ARA framework for engineering knowledge graphs is presented. In Section 3, related work is discussed. Section 4 presents our approach towards knowledge management, and TOXIN’s knowledge management system and the various tools developed so far are explained and demonstrated in Section 5. The chapter ends with conclusions and future work, which are presented in Section 6.
2. Background
In this section, we provide the background of the work. We start by briefly explaining the concepts of a knowledge graph, an ontology, and a vocabulary. Thereafter, we present the ARA framework on which our knowledge management system is based.
2.1 Knowledge graph, ontology, and vocabulary
Knowledge graphs use the concept of a graph to describe knowledge of the real world. In graphs, knowledge is represented with nodes and edges where nodes represent entities for the real world and edges represent the relationships between entities [4]. An edge between two entities is called a triple. A triple is an ordered grouping of a subject, a predicate, and an object. A triple or set of triples can be seen as a directed edge-labelled graph called a data graph. A data graph may be identified by a name. Formally, such a named graph is represented by a pair
Graphs can be gathered into a graph dataset. A graph dataset is not composed of triples but rather by quadruples (or
The Resource Description Framework (RDF) [5] is a W3C-recommended abstract graph data model that allows representing data graphs. A set of triples expressed in RDF is called an RDF graph, which can be stored in a named graph.
An ontology can be (re)used or developed to specify which type of knowledge is stored in the knowledge graph [6]. An ontology describes concepts in a domain, the properties of the concepts, the relations between the concepts, and the domain rules that apply to them. In other words, an ontology aims to model a domain with as much precision as possible. In this way, the ontology can be used as a model for the knowledge to be stored, and the knowledge stored can be considered as an instantiation of the ontology [6, 7]. In this case, the knowledge graph is called an
Not all knowledge graphs require expressive ontology languages, which come at additional computational costs. Another way to represent the semantics of the relationships within the data graph is using one or more
2.2 Ontology-based knowledge graph
As explained in the previous subsection, an ontology-based knowledge graph is a knowledge graph where one or more ontologies are used to define which type of knowledge can be stored in the knowledge graph [6].
Note that sometimes, the instances of the concepts and relationships defined in the ontology (i.e. the “real” data) are also considered as part of the ontology, removing the strict separation between model and data. However, we follow the approach proposed by Chasseray et al. in Ref. [7], where the distinction between model and “data” is kept: A knowledge graph is composed of a
Furthermore, Chasseray et al. [7] combine ontologies with the OMG’s Model-Driven Engineering (MDE) approach. MDE defines four modelling levels: data level, model level, meta-model level, and meta-metamodel level [10]. Following this MDE approach, three levels are considered for ontology modelling by Chasseray et al.: an instantiated ontology (i.e. the data level) is defined by a domain ontology (i.e. the model level), which is an instantiation of an

Figure 1.
Ontology-based knowledge graph structure based on the Model-Driven Engineering (MDE) approach (adapted from [
2.3 Abstract reference architecture
In Ref. [3], the Abstract Reference Architecture (ARA) is introduced to define the main processes and tasks required during the life cycle of knowledge graphs. ARA consists of three layers:
ARA distinguishes four sub-tasks in the Knowledge Acquisition and Integration Layer:
Schema Development ,Data Lifting ,Data Annotation , andQuality Assurance . According to ARA, the first task is Schema Development (i.e. the development of the domain ontology). Data Lifting transforms raw data (e.g. stored in spreadsheets or classical databases) into semantic data. Data Annotation deals with linking and enriching the data with other relevant sources (e.g. other ontologies, knowledge graphs, vocabularies, or even classical databases), resulting in interlinked and contextualised semantic data. Quality assurance is about ensuring that the knowledge graph is of good quality, as one must rely on accurate data5. In Figure 2, one can see that the outcome of each of these activities informs the other. For instance, when the schema evolves, the transformation and integration of data into the knowledge graph may need to be updated.The Knowledge Storage Layer deals with the storage of the knowledge graph. Two main architectural options are mentioned in Ref. [3]: (1) reusing existing data storage and providing mappings between the ontology and the data schemes of the existing storage and (2) using a graph-based data store.
The Knowledge Consumption Layer provides tools for interested parties to access the knowledge. Examples include search and querying tools.
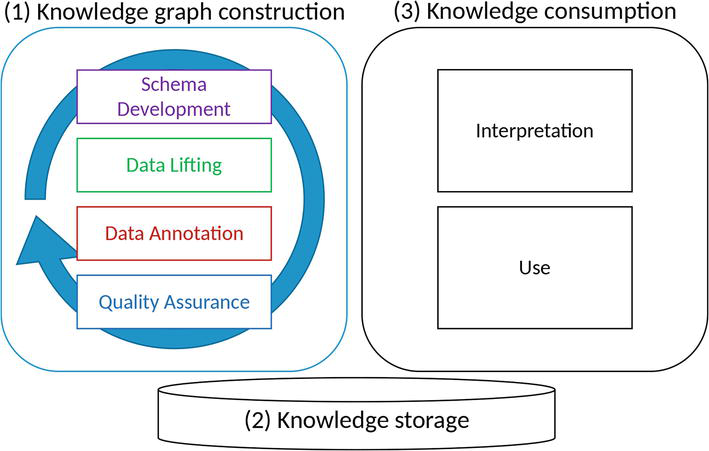
Figure 2.
The architecture of a knowledge graph project depicting the various processes and tasks in knowledge graph engineering, based on Ref. [
3. Related work
3.1 Existing tools for supporting hazard assessment
Because the aim of the TOXIN knowledge system is to support the hazard assessment of new cosmetic ingredients, we first discuss existing tools in this context.
There are several approaches to hazard assessment, and various tools have been developed to support this process. One such tool is the OECD QSAR Toolbox [11], which is a software application that aims to classify chemicals based on their structural characteristics and potential toxic mechanisms of interaction. In this way, this toolbox can provide some support for hazard assessment.
COSMOS NG [12] is another tool and provides a database of toxicity opinions about several chemicals that can be used for hazard assessment. COSMOS NG also provides
VEGA HUB6 includes several
There are other web applications available providing information for a more accurate and animal-free hazard assessment with a focus on one single endpoint, e.g. Vienna Livertox workspace7, or on multiple endpoints, e.g. SApredictor8 and ICE9.
In a broader context, there is a growing interest in developing standardised vocabularies and ontologies that can be used to represent data about different toxicity tests efficiently [13]. The OpenTox initiative [14] aims to provide a framework for integrating and analysing diverse data sources using an ontology to improve the predictability of toxicology models and support decision-making in chemical safety assessment.
Tox21 [15] is a research program that seeks to identify new mechanisms of chemical activity in cells and use this information to prioritise untested chemicals for further evaluation and to develop more accurate predictive models of human response to toxic substances. One purpose is to provide a screening tool that would quickly identify potential hazards amongst a long list of potentially toxic compounds.
The work conducted in TOXIN has similarities with the previously mentioned initiatives. However, it is different in the sense that the main aim of our knowledge management system is to have a tool that can support toxicologists in the
3.2 Work on linking data related to toxicology
Numerous studies focused on linking data related to toxicology: Ref. [16] focuses on a comprehensive map of disease-symptom relations, Ref. [17] presents a method for representing the organisation of human cellular processes in a network and mapping diseases onto this network, and Ref. [18] provides an overview of existing work on integrating genes, pathways, and phenotypes to understand the effects of gene mutations better. While these studies are valuable contributions to the toxicology domain, they are specific. Moreover, their approaches may not necessarily apply to the broader task of integrating different available data sources.
4. Approach
As already explained in the introduction, our approach to knowledge management and the tools developed for it are based on the Abstract Reference Architecture (ARA).
Figure 3 provides an overview of the tasks defined for our knowledge management system. As described by ARA, the process starts with the Knowledge Graph Construction process that consists of four tasks: Ontology Development, Data Lifting, Data Annotation & Enrichment, and Quality Assurance.
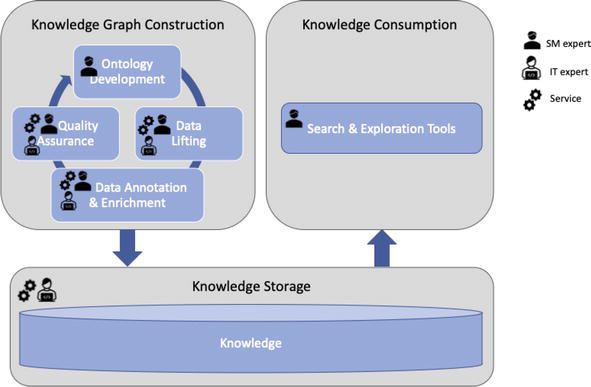
Figure 3.
TOXIN’s knowledge Management approach adapted from Ref. [
Ontology Development is concerned with developing the knowledge graph’s schema, which is done by means of an ontology, created with an ontology language. As already indicated, we follow [6, 7] in the sense that a knowledge graph is the combination of a schema (i.e. an ontology) and an instantiation of that ontology (i.e. the data).
The term data lifting is used in ARA to denote the activities related to populating the knowledge graph. We have foreseen different ways to populate the knowledge graph in our knowledge management system. Subject matter experts can enter data manually. However, importing data from non-RDF sources, i.e. from spreadsheets, is also possible.
In ARA, Data Annotation comprises the activities of linking concepts and data with other relevant sources (e.g. other ontologies, knowledge graphs, vocabularies, or even classical databases), resulting in interlinked semantic data. We have called this task “Data Annotation & Enrichment” to better emphasise that data annotation also includes linking the data to existing sources. Some data annotation activities can be done manually by subject matter experts, but linking for the purpose of enrichment can be more complicated and may need the help of IT experts, although tools can also be developed for (semi-) automatic data annotation & enrichment.
Quality assurance is about ensuring that no mistakes are introduced into the knowledge graph and its ontology. This is a complex issue. In general, it concerns two aspects [20]: (1) the question of whether the knowledge graph has been built correctly, i.e. according to the requirements, and (2) the question of whether the right knowledge graph has been built, i.e. does the ontology correctly reflect the domain and does it contain correct data? Some quality control can be performed by subject matter experts, more technical aspects can be controlled by IT experts, but manual quality control is time-intensive. Tools could be helpful in this respect.
The Knowledge Storage process deals with the storage of the knowledge graph. In this process, we decide how to store and service the data to the various applications built on top of this knowledge graph. Since we build a knowledge graph with semantic technologies (i.e. RDF as the graph data model and Semantic Web ontology languages), we use a triplestore. A triplestore is a name commonly given to RDF graph databases.
The Knowledge Consumption provides query, search, & exploration functionality.
For the tools, we have followed an end-user approach as much as possible [19]. This is done because the direct use of semantic technology is often complicated for subject matter experts who are not technologically skilled. IT experts can be called in, but for specialised domains, such as the toxicology domain, it may take a long time before IT experts have familiarised themselves with the domain. In addition, an IT expert needs to stay available for the complete lifetime of the knowledge management system as knowledge systems tend to evolve over time, e.g. new properties, relationships, and concepts may be needed, and new data must be added. Furthermore, during the Knowledge Consumption process, the assistance of IT experts may be needed, e.g. for the formulation of (new) queries or for the development of (new) reasoning support. To avoid being largely or completely dependent on IT experts, we developed end-user tools where possible. This means that subject matter experts who are not skilled in Computer Science (in our case, toxicologists) should be able to use these tools with some minimal training. Ideally, all tasks in ARA should be accessible to subject matter experts; however, this seems not feasible for some tasks. In particular, automatic Data Lifting, automatic Data Annotation & Enrichment, Quality Assurance, and Knowledge Storage may require the assistance of IT experts. For the ontology development and the manual data input, we used the jigsaw metaphor [21]. The purpose of using this metaphor was to hide the technicalities of the semantic technology.
In Figure 3, three different icons are used to indicate who can perform the tasks. If a subject matter (SM) expert can perform the task, the SM expert icon is used, for instance, an SM expert can query the knowledge storage. The IT expert icon indicates that an IT expert should perform the task or at least be involved. The service icon is used to indicate that a (part of a) task can be done automatically. For instance, Data Lifting, Data Annotation & Enrichment and Quality Assurance have all three icons meaning that these tasks can be partially done by subject matter experts, partially by IT experts, and partially automated.
5. TOXIN’s knowledge management system
We present the tools developed for the knowledge management system of TOXIN in this section. Recall that the ultimate goal of this knowledge management system is to support toxicologists in the hazard assessment of new compounds by bringing together multiple sources of available toxicological information into a knowledge graph and allowing them to query and search the graph.
The first aim was to gather information about toxicity tests, described in documents dossiers, called Safety Evaluation Opinions, issued by the Scientific Committee on Consumer Safety (SCCS) about cosmetic ingredients in a knowledge graph. Each dossier contains information about experiments (also called tests) of a compound mainly conducted on laboratory animals. The information includes the quantity of the compound tested, how it was inoculated, the species on which the compound was tested, and so on. The dossiers also include information on the outcome of these tests, as well as the authors’ opinions about the compound’s toxicity. The data contained in these dossiers are stored in an ontology-based knowledge graph to provide more efficient access to this data for toxicologists.
The second aim is to enrich this knowledge graph with information from other relevant sources in the toxicology domain.
Because the development of the knowledge management system is based on ARA, we describe the tool support for the different tasks in ARA described in Section 4.
5.1 Ontology development support
While ontology development is one of the tasks within our approach, we want to emphasise that the purpose of this step is not to allow toxicologists to create full-fledged domain ontology but to set up an ontology-based knowledge graph, where the role of the ontology is to define the organisational structure of the knowledge graph. The ontology that needs to be developed corresponds more with a vocabulary rather than a highly axiomatised ontology. Therefore, the expressiveness of the developed tool is kept limited with the aim to curb the learning curve for the toxicologists.
The tool developed for defining a domain ontology is a web-based application built on top of Apache Jena. The jigsaw metaphor [21], used in the tool to hide the technicalities of the semantic technology used, is implemented via the Google Blockly JavaScript library. The tool is not limited to the toxicology domain, but can also be used for other domains to define the ontology for an ontology-based knowledge graph. It is described in detail in [19, 22]. Here, we provide a short description to show the reader how the tool is used to develop the ontology of TOXIN’s knowledge management system.
A predefined jigsaw block is provided to allow toxicologists to define the domain concepts in the ontology by themselves. In this way, toxicologists can easily define the domain concepts for which they will maintain information in the knowledge graph. An example of such a domain concept is “Repeated Dose Toxicity”, which is used extensively in Safety Evaluation Opinions. Figure 4 shows the web page for defining this domain concept. On the left-hand side of the page, one can see the predefined jigsaw block (i.e. top-level blue block “Domain Concept”) that allows specifying the domain concept. Properties can be added by dragging and dropping the empty
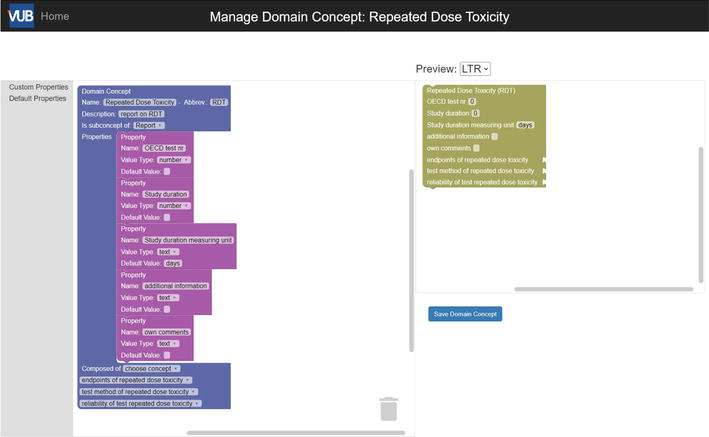
Figure 4.
Screenshot of the domain concept definition page.
A domain concept can be composed of other domain concepts. In Figure 4, we see that the toxicologist specified that the
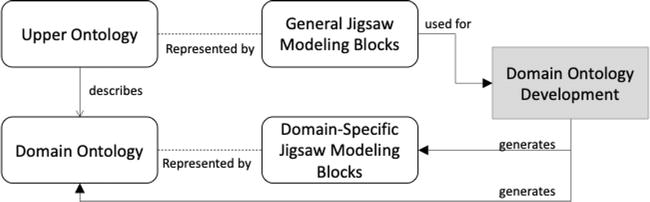
Figure 5.
Ontology Development Process Using the Jigsaw Metaphor (taken from [
5.2 Data lifting support
The current purpose of the Data Lifting task of the TOXIN knowledge management system is to capture, in the knowledge graph, information about
5.2.1 Manual data lifting
The first way to do this is by manually entering the information while reading a Safety Evaluation Opinion. For this, a toxicologist can use the domain-specific jigsaw blocks generated for the different domain concepts defined in the ontology. For example, when a toxicologist wants to enter the information from a particular Safety Evaluation Opinion document, they use the domain-specific jigsaw blocks created during the Ontology Development Process for Safety Evaluation Opinions (described in the previous section) to compose a so-called

Figure 6.
Jigsaw Block composed for the dossier “Tetrabromophenol Blue”.
In order to save time during the manual entering of data and also to ensure that similar data is always entered in the same way, the tool allows the user to save block structures so that they can be reused in multiple dossiers as is. For example, the “Repeated Dose Toxicity” block shown in Figure 6 could be saved as a block structure. Then this block and all its sub-components (i.e. blocks attached to its right) will appear in the tab “saved block structures” depicted in Figure 7. These saved block structures can be dragged and dropped as a whole, which saves time when composing another dossier.

Figure 7.
Screenshot of the dossier creation page’s saved block structure tab.
5.2.2 Automatic data lifting
In the past, the toxicologists of the TOXIN project used spreadsheets to structure and store information from Safety Evaluation Opinions. Because a considerable amount of time was spent on creating these spreadsheets, it was decided to develop a tool to import the data into the knowledge graph automatically.
We have used R2RML to transform the spreadsheets into RDF. R2RML is a W3C Recommendation for transforming relational data into RDF. Although spreadsheets are not relational databases, once stored as comma-separated values (CSV) files, they can be considered as containing relational data (i.e. rows with attributes). R2RML engines (and dialects) such as RML [23] and R2RML-F [24] provide support for CSV files. We have chosen to adopt R2RML-F as this particular engine loads the CSV files into an in-memory relational database, which allows manipulating the data in the records with SQL prior to generating RDF.
The only requirement is that the CSV files are well-formed (e.g. the first row contains the names of attributes and no duplicates are allowed). This requirement is ensured by the people curating the spreadsheets. The advantage of using R2RML is that when new spreadsheets need to be transformed into RDF, one only needs to specify new R2RML mappings (which can be done by an IT expert). So far, data from 93 scientific opinions dealing with 88 different cosmetic ingredients, published between 2009 and 2019 by SCCS, were imported this way.
5.3 Data annotation and enrichment support
The current purpose of the task is to facilitate access to relevant toxicological data and provide answers to specific questions that the toxicologists formulated (see below). In a later stage, the annotations and enrichment could be used for AI-based reasoning.
First, simple manual data annotation is possible while defining the ontology and entering data. For a dossier, a link to the Safety Evaluation Opinion file for which the dossier is created should be given. For a domain concept, an IRI referring to a relevant source can be provided (see Figure 8). When references to other ontologies or RDF datasets are provided, users effectively create Linked Data11.
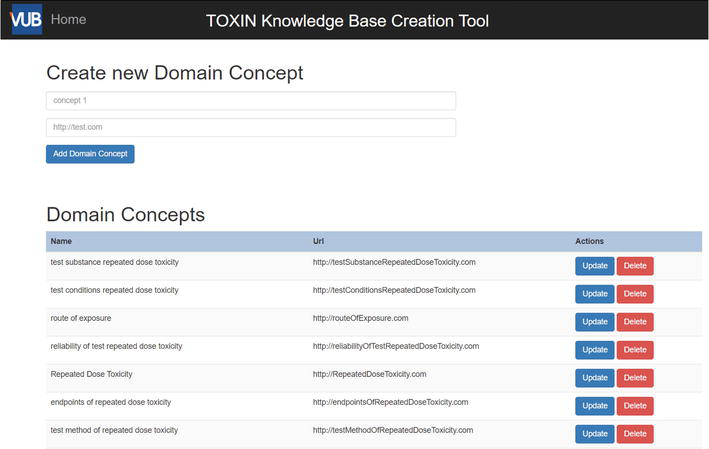
Figure 8.
Web page for domain concept creation and modification showing IRIs to related sources.
Furthermore, a method for integrating multiple toxicological data sources and linking them with the TOXIN knowledge graph has been developed and applied [25]. The method starts with identifying the desired capabilities of the enriched knowledge management system by means of so-called Competency Questions [26]. Currently, the following competency questions have been formulated:
Knowing some adverse effects observed in a subject, what diseases or toxic processes may affect this subject?
Which biological processes or pathways are affected by a certain disease?
The functioning of what gene or protein is impaired by some toxic process?
These questions helped to select the potential sources for the enrichment. In collaboration with the toxicologists, the following sources were selected: TXPO [27], OGG [28], Uniprot [29], Reactome [30], Kegg [31], and CTD [32]. We furthermore identified the Gene Ontology (GO) [33] and Gene Ontology Causal Activity Modelling (GO-CAM) [34]. GO is a comprehensive and structured data source that classifies and describes genes and gene products based on their biological functions, cellular locations, and molecular activities. GO is a resource that many of the other initiatives reference in their data.
The ToXic Process Ontology (TXPO) is an ontology designed to represent causal relationships between toxic processes. Its purpose is to clarify the toxicological mechanisms from latent to toxic manifestations in order to help in drug development. Similar to TOXIN, their current focus is on the liver, as it has been identified as one of the most affected organs upon oral administration of cosmetic ingredients to animals [35].
TXPO contains a set of human genes that are imported from the Ontology of Genes and Genomes (OGG). This ontology focuses on offering classes and relationships to represent genes and genomes in different organisms. TXPO only imports the genes related to human organisms. TXPO also contains entities and relationships from the Gene Ontology (GO) [33]. The goal of this ontology is to represent the functions of genes. To create relationships between a toxic process and the genes or proteins affected by this process, GO is the perfect intermediate. Some links already exist in TXPO between a toxic process and the natural processes that it affects. For this, GO annotations are used that represent the link between a GO term, i.e. a biological role and a gene product (gene or protein) that assumes this role in the organism. Each annotation is associated with a proof, which has a weight representing the confidence in the annotation. We considered the integration of annotations from two sources: OGG and from the gene ontology resource12. This resource regroups annotations made for a large variety of species and from several different sources. We chose to integrate only human gene products from UniProt.
GO-CAM is developed by the GO community and is a modelling approach that builds upon GO. GO-CAM introduces models to connect GO annotations to represent causal relationships between gene products and biological processes, providing a more detailed and explicit representation of molecular events. The GO-CAM approach allows for the representation of specific regulatory interactions and signalling pathways, enabling researchers to analyse and interpret biological data in a more precise and context-dependent manner. For example, a GO-CAM model could show that the hyper-function of a biological process positively regulates another process. These relationships allow toxicologists to track a toxic effect from its starting point to all the other elements that are indirectly affected. GO-CAM is thus an interesting resource to represent the different relationships between biological processes.
Reactome and Kegg are two well-known pathways repositories. To integrate pathways from both repositories, we used associations from the Comparative Toxicogenomics Database (CTD). CTD combines biological data by manually curating and linking information from published literature. It offers several files containing the relationships between different biological entities, and for TOXIN, we used the disease pathway association file.
To perform the integration of (parts of) the different sources, we defined an upper structure, which is based on the TXPO ontology that has been developed to be used as a structure to build ontology-based knowledge graphs. While TXPO offers a set of classes and axioms, i.e. an ontology, we wanted to use the identifiers of these classes as individuals. Luckily, using semantic technology allows us to reuse these identifiers in a different ontology—our upper structure.
For the integration, we have chosen to maintain the original IRIs to uniquely identify the resources they describe and maintain the authority of the original sources. However, for the additional links and entities created for the integration, we have designed our own named graphs to describe them. This choice allows us to clearly distinguish between original resources and those added as part of the integration. This architecture is illustrated in Figure 9.
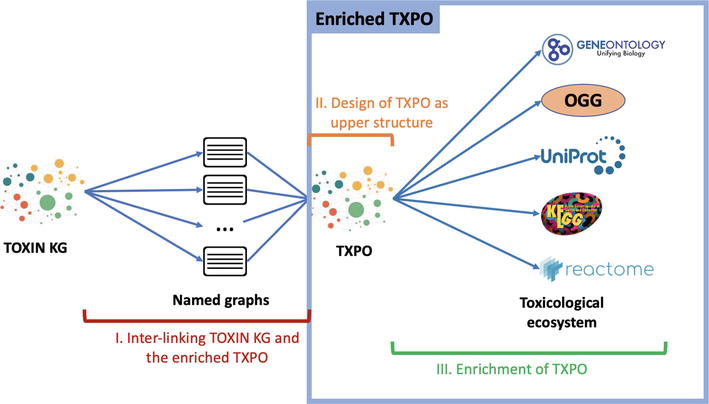
Figure 9.
Schema of TEKG with the relations between TOXIN KG and the enriched TXPO.
The decision to retain the authoritative resources’ IRI whenever possible allows access to additional information about entities in the knowledge graph from the original data source. An example of this can be seen in Figure 10. On the left of the figure, we can see three entities of the enriched knowledge graph represented with Ontodia (see Section 5.6 for more details about Ontodia). When the IRIs of these entities are visited, e.g. by clicking on them and loading the resource in a Web browser, the resources on the right of the image appear. This illustrates that we can access the source data through the IRI representing an entity. In other words, not only are the resources conceptually integrated, we even have “integrated” systems thanks to the distributed graph data model offered by RDF.
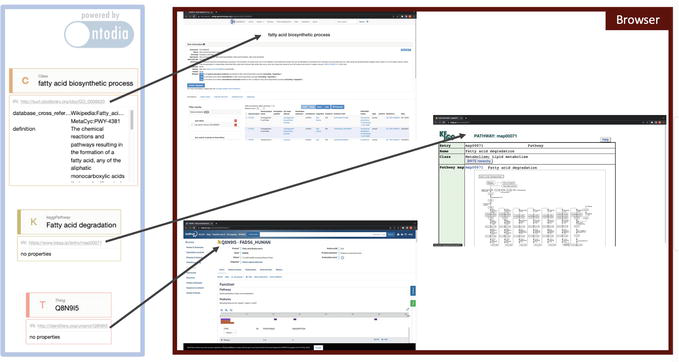
Figure 10.
Illustration of the possibility of accessing the external sources from which data was integrated through the IRIs.
Concerning the linking of the TOXIN knowledge graph and the enriched TXPO, two kinds of links can be made. Firstly, direct links can be made between an effect observed in a dossier and the same effect present in the enriched TXPO. Secondly, from the observations and the conclusions in a dossier, a domain expert (who has the knowledge to infer the toxic effects from the observations) can infer “indirect” links between the dossier and the toxic effects or diseases that affect the test animal. There is no absolute knowledge about how to link some observations and a toxic effect, and errors can occur. Therefore, the links are stored in different named graphs. Each graph corresponds to an individual, a group, or a particular knowledge responsible for defining the links that it contains. In this way, it is possible to query only some of these links depending on who made them and on what ground. This type of linking is a manual process. Another approach is to create these links automatically. For the direct links, it is straightforward. The task is to infer the relations owl:sameAs between the TOXIN knowledge graph and the enriched TXPO, and tools exist to find these relations, such as Silk [36] and Alignment API [37]. Concerning the “indirect” links, some rule-based mechanisms could be put in place. This is subject to future work.
5.4 Quality assurance support
Currently, the support for quality assurance is limited in our tool to manual quality checking and the validation of the structure of the data in the knowledge graph by means of SHACL shapes. With SHACL [38], a W3C Recommendation, one can validate RDF graphs, i.e. one can validate the structure of triples in a Closed World Setting. SHACL provides a set of “core” constructs for declaring rules (value- and data type checking, cardinality, value ranges, comparisons,… which can be combined with a set of logical operators). Validating the knowledge graph with SHACL is especially valuable in the case of the automatic import of the spreadsheets’ data. A SHACL shape is a subset of an RDF graph, which can be declared, and to which one can add constraints.
Because we cannot expect that toxicologists can formulate constraints in SHACL, we looked for an approach by which the SHACL shapes and constraints can be generated. How this is achieved is explained in [19].
5.5 Knowledge storage
While quite a few triplestores are available (both free, commercial, and free for research purposes), we have adopted Apache Fuseki13 for managing the storage of triples, named graphs, and SPARQL endpoints. The ontology is stored in one named graph. The data that have been lifted are stored in another. Data that have been integrated from other sources with the enrichment scripts are also stored in dedicated named graphs. This allows us to separate the ontology and the data, and to ensure that data from various sources (and possibly with different interpretations) are not mixed up.
5.6 Knowledge consumption support
Knowledge consumption concerns the access and use of the knowledge graph by end-users. The primary use of TOXIN’s knowledge graph is to provide liver-specific toxicological information. For this purpose, a web tool has been developed that allows one to search TOXIN’s knowledge graph from two perspectives; from the perspective of chemical compounds and from the perspective of health effects.
In the first perspective, one can search the knowledge graph for dossiers (i.e. Safety Evaluation Opinions) about specific compounds by means of the CAS number, INCI name, or SMILES string of the compound. For example, HC Yellow n° 2 can be found using the INCI name “HC Yellow n° 2”, the CAS no 4926-55-0, or the SMILES string “C1 = CC=C(C(=C1)NCCO)[N+](=O)[O-]”. As a result, a summary of information on the searched compound is given; an interface to the OECD QSAR toolbox is provided to select information from this toolbox for the compound, e.g. the Hazard Evaluation Support System (HESS)
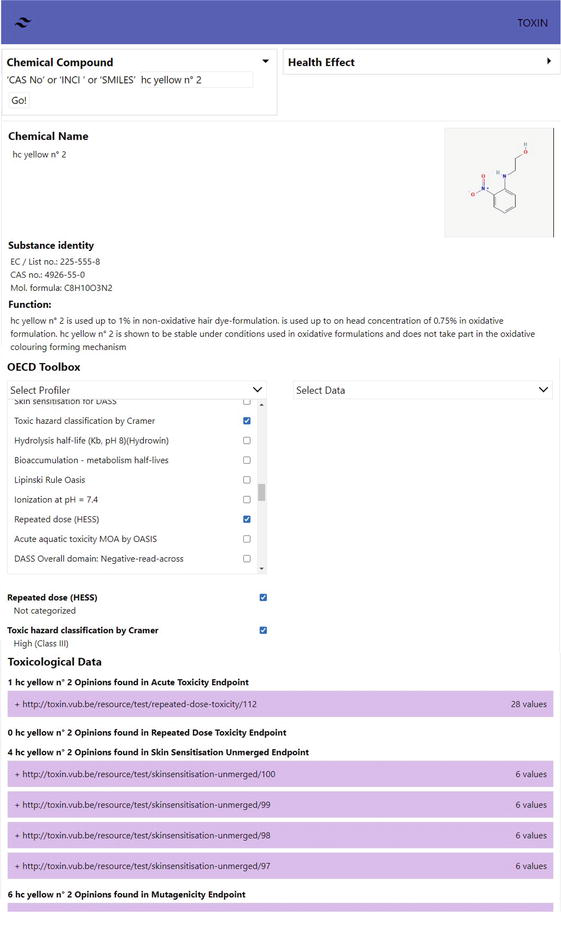
Figure 11.
Partial screenshot of the search result of the chemical compound “HC Yellow n° 2”.
In the second perspective, the user can search for compounds with dossiers mentioning a specific toxicological outcome by selecting a health endpoint. For the moment, the endpoints acute toxicity, repeated dose toxicity, and toxicokinetics are supported by the tool. As a result, in the “compound view” all relevant dossiers ordered by compound are listed (see Figure 12 below); the “Opinions view” lists the relevant dossiers (i.e. opinions) directly (similar to the bottom part of Figure 11). The user can easily filter the output by the type of test conducted (
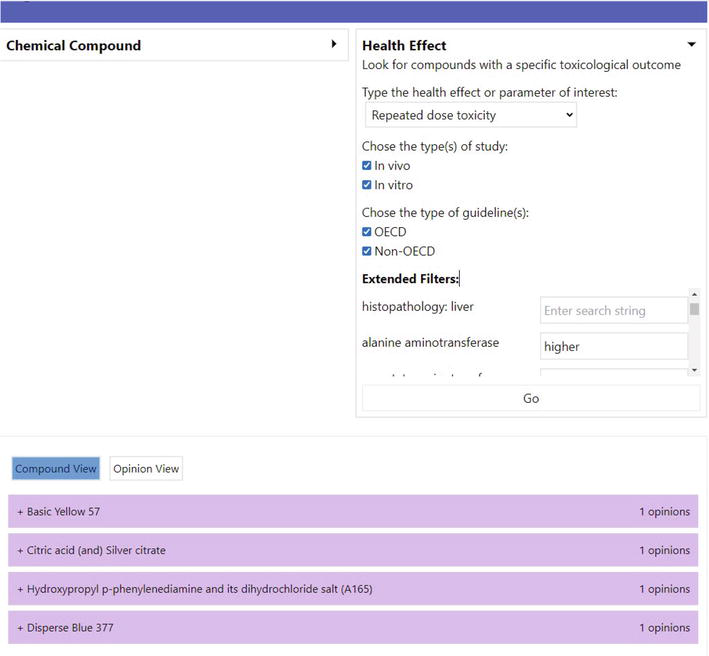
Figure 12.
Screenshot of the search by Health Effect: “Repeated Dose Toxicity”.
A dedicated tool for querying and searching the enriched Knowledge graph described in Section 5.3 has yet to be developed, but an existing tool, Ontodia [39], has been used to show that the competency questions formulated by the toxicologists can be answered. Ontodia is a tool allowing one to visually explore a triple-based knowledge graph using diagrams and faceted browsing, providing a way to navigate knowledge graphs (note that there exist other tools that could also be used for this purpose, such as WebVOWL14). In Figure 13, we illustrate the answer to the competency question “Knowing some adverse effects observed in a subject, what diseases or toxic processes may affect this subject?” Figure 13 presents different adverse effects that could be observed during a toxicological test, such as “Increasing blood ALP concentration”. These adverse effects are linked to toxic courses or diseases with the predicates “has part” and “has context”. These predicates allow one to query all the toxic courses for which an adverse effect could be observed. Moreover, relationships between toxic processes are represented. However, it not only allows for finding toxic processes related to an adverse outcome, but it also allows for the examination of the relationships between adverse effects, toxic effects, toxic courses, and diseases.
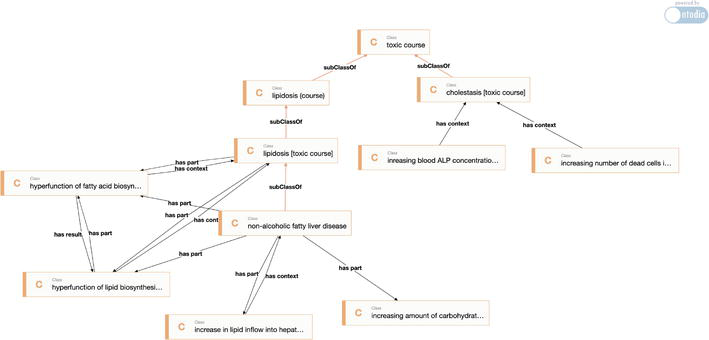
Figure 13.
Illustration of how the enriched knowledge graph can be used to answer the competency question “Knowing some adverse effects observed in a subject, what diseases or toxic processes may affect this subject?”.
6. Conclusions
In this chapter, we presented the knowledge management system developed in the TOXIN project to support toxicologists in the animal-free hazard assessment of new cosmetic compounds. The developed knowledge management system is based on the tasks defined for creating, maintaining, and exploiting knowledge graphs in the Abstract Reference Architecture (ARA), which defines the main processes and tasks required during the life cycle of knowledge graphs. The knowledge system is developed as a knowledge graph by means of semantic technology, and tools were developed for the following ARA tasks: the Ontology Development, Data Lifting, Data Annotation & Enrichment, Quality Assurance, and Knowledge Consumption.
In addition, special attention has been paid to the fact that subject matter experts, i.e. toxicologists, should be able to perform most of the tasks by themselves. Where possible, the tools shield the non-IT users as much as possible from the technical aspects of the technology used and they are able to use these tools with some minimal training. For the tasks for which this was impossible, automatic tools were developed where possible.
The different developed tools have been described. Two tools are provided for defining the knowledge graph and populating it with data. First, we have developed an end-user tool, based on the jigsaw metaphor, that allows the manual definition and population of a knowledge graph by toxicologists. In addition, we developed a tool to automatically import toxicity data previously collected by the subject matter experts in spreadsheets into the knowledge graph. A search and query tool has been developed that allows toxicologists to explore and search in the knowledge graph by means of a simple web-based user interface and without the need to use the technical query language SPARQL. Furthermore, we integrated multiple data sources from the field of toxicology into the TOXIN knowledge graph to further support the hazard assessment of new compounds. For exploring this enriched knowledge graph, an existing tool, i.e. Ontodia, is currently used. Finally, we investigated an approach to deal with some aspects of the quality assurance of the knowledge graph.
For future work, we are considering the use of Natural Language Processing (NLP) techniques for different tasks. We observed that relying solely on text matching for searching in the knowledge graph is insufficient, especially when seeking knowledge from diverse sources. For example, if a toxicologist wants to know which chemical compounds raise the value of a particular observation, they might search using the term “increase”, however, given that different terminology is used to describe this effect, such as “growth” or “change”, they will miss a few search results. In addition, sometimes results of tests are entered all together as one large text block rather than as separate results. Sometimes a value was even considered as a concept or the other way around when entering the knowledge, which means that searching should not be limited to the values of properties but also the names of concepts and properties should be considered.
Last but not least, other future work concerns the addition of a data provenance layer [40] to our knowledge graph, which will allow to trace who has added which information and when.
Acknowledgments
The TOXIN project is financially supported by Vrije Universiteit Brussel under Grant IRP19.
Some funding came from Cosmetics Europe and the European Chemical Industry Council (CEFIC).
The research of Audrey Sanctorum has been funded by an FWO Postdoc Fellowship (1276721 N) of the Research Foundation Flanders.
Acronyms
alkaline phosphatase | |
abstract reference architecture | |
chemical abstracts service | |
comparative toxicogenomics database | |
comma-separated values | |
European Commission | |
good laboratory practice (GLP) | |
gene ontology | |
gene ontology causal activity modelling | |
hazard evaluation support system | |
International nomenclature cosmetic ingredients | |
Internationalised resource identifier | |
Information technology | |
model-driven engineering | |
natural language processing | |
organisation for economic co-operation and development | |
ontology of genes and genomes | |
object management group | |
web ontology language | |
relational database to RDF mapping language | |
extension of R2RML | |
resource description framework | |
resource description framework schema | |
RDF mapping language | |
scientific committee on consumer safety | |
shapes constraint language | |
subject matter | |
simplified molecular-input line-entry specification | |
standard query language and protocol for RDF triplestores | |
structured query language | |
non-animal methodologies for toxicity testing of chemical compounds | |
toxic process ontology | |
user interface | |
world wide web consortium |
References
- 1.
Ball N, Bars R, Botham PA, Cuciureanu A, Cronin MTD, Doe JE, et al. A framework for chemical safety assessment incorporating new approach methodologies within REACH. Archives of Toxicology. 2022; 96 (3):743-766 - 2.
Rajpoot K, Desai N, Koppisetti H, Tekade M, Sharma MC, Behera SK, et al. Chapter 14 - In silico methods for the prediction of drug toxicity. In: Pharmacokinetics and Toxicokinetic Considerations, Vol. 2 of Advances in Pharmaceutical Product Development and Research. Cambridge, Massachusetts, USA: Academic Press; 2022. pp. 357-383 - 3.
Denaux R, Ren Y, Villazón-Terrazas B, Alexopoulos P, Faraotti A, Honghan W. Knowledge architecture for organisations. In: Pan JZ, Vetere G, Gómez-Pérez JM, Honghan W, editors. Exploiting Linked Data and Knowledge Graphs in Large Organisations. Cham, Switzerland: Springer; 2017. pp. 57-84 - 4.
Hogan A, Blomqvist E, Cochez M, d’Amato C, de Melo G, Gutiérrez C, et al. Knowledge Graphs. Number 22 in Synthesis Lectures on Data, Semantics, and Knowledge. Switzerland: Springer; 2021 - 5.
Wood D, Cyganiak R, Lanthaler M. RDF 1.1 Concepts and Abstract Syntax. W3C Recommendation. USA: W3C; 2014. Availabale form: https://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/ - 6.
Hepp M. Ontologies: State of the art, business potential, and grand challenges. In: Hepp M, De Leenheer P, de Moor A, Sure Y, editors. Ontology Management, Semantic Web, Semantic Web Services, and Business Applications, Vol. 7 of Semantic Web and Beyond: Computing for Human Experience. Boston, MA, USA: Springer; 2008. pp. 3-22 - 7.
Chasseray Y, Barthe-Delanoë A-M, Négny S, Le Lann J-M. A generic metamodel for data extraction and generic ontology population. Journal of Information Science. 2021; 48 (6):838-856. DOI: 10.1177/0165551521989641 - 8.
W3C OWL Working Group. OWL 2 Web Ontology Language Document Overview. W3C Recommendation. USA: W3C, Word Wide Web Consortium; 2012. Available form: https://www.w3.org/TR/2012/REC-owl2-overview-20121211/ - 9.
Guha R, Brickley D. RDF Schema 1.1. W3C Recommendation, W3C; 2014 - 10.
Colomb RM, Raymond K, Hart L, Emery P, Welty C, Xie GT, et al. The object management group ontology definition metamodel. In: Ontologies for Software Engineering and Software Technology. Berlin, Heidelberg: Springer; 2006. pp. 217-247 - 11.
Dimitrov SD, Diderich R, Sobanski T, Pavlov TS, Chankov GV, Chapkanov AS, et al. QSAR Toolbox - workflow and major functionalities. SAR and QSAR in Environmental Research. 2016; 27 :203-219 - 12.
Yang C, Cronin MTD, Arvidson KB, Bienfait B, Enoch SJ, Heldreth B, et al. COSMOS next generation – A public knowledge base leveraging chemical and biological data to support the regulatory assessment of chemicals. Computational Toxicology. 2021; 19 :100175 - 13.
Hardy B, Apic G, Carthew P, Clark D, Cook D, Dix I, et al. Toxicology ontology perspectives. ALTEX. Alternatives zu Tierexperimenten. 2012; 29 (2):139-156 - 14.
Tcheremenskaia O, Benigni R, Nikolova I, Jeliazkova N, Escher S, Batke M, et al. OpenTox predictive toxicology framework: Toxicological ontology and semantic media wiki-based OpenToxipedia. Journal of Biomedical Semantics. 2012; 3 (Suppl 1):S7 - 15.
Thomas RS, Paules RS, Simeonov A, Fitzpatrick SC, Crofton KM, Casey WM, et al. The US Federal Tox21 Program: A strategic and operational plan for continued leadership. ALTEX - Alternatives to animal experimentation. 2018; 35 (2):163-168 - 16.
Zhou X, Menche J, Barabási A-L, Sharma A. Human symptoms–disease network. Nature Communications. 2014; 5 (1):1-10 - 17.
Stoney R, Robertson DL, Nenadic G, Schwartz J-M. Mapping biological process relationships and disease perturbations within a pathway network. npj Systems Biology and Applications. 2018; 4 (1):22 - 18.
Papatheodorou I, Oellrich A, Smedley D. Linking gene expression to phenotypes via pathway information. Journal of Biomedical Semantics. 2015; 6 (1):17 - 19.
Sanctorum A, Riggio J, Maushagen J, Sepehri S, Arnesdotter E, Delagrange M, et al. End-user engineering of ontology-based knowledge bases. Behaviour & Information Technology. 2022; 41 (9):1811-1829 - 20.
Vrandecic D. Ontology evaluation. In: Staab S, Studer R, editors. Handbook on Ontologies, International Handbooks on Information Systems. Berlin, Heidelberg: Springer-Verlag; 2009. pp. 293-313 - 21.
Gozzi R. The jigsaw puzzle as a metaphor for knowledge. ETC: A Review of General Semantics. 1996; 53 (4):447-451 - 22.
Sanctorum A, Riggio J, Sepehri S, Arnesdotter E, Vanhaecke T, De Troyer O. A Jigsaw-based end-user tool for the development of ontology-based knowledge bases. In: Fogli D, Tetteroo D, Barricelli BR, Borsci S, Markopoulos P, Papadopoulos GA, editors. Proceedings of IS-EUD 2021, 8th International Symposium on End-User Development, Vol. 12724 of Lecture Notes in Computer Science. Cham, Switzerland: Springer; July 2021. pp. 169-184 - 23.
Dimou A, Sande MV, Colpaert P, Verborgh R, Mannens E, Van de Walle R. RML: A generic language for integrated RDF mappings of heterogeneous data. In: Bizer C, Heath T, Auer S, Berners-Lee T, editors. Proceedings of the Workshop on Linked Data on the Web co-located with the 23rd International World Wide Web Conference (WWW 2014), Seoul, Korea, April 8, 2014. Vol. 1184 of CEUR Workshop Proceedings. Aachen, Germany: CEUR-WS.org; 2014 - 24.
Debruyne C, O’Sullivan D. R2RML-F: towards sharing and executing domain logic in R2RML mappings. In: Auer S, Berners-Lee T, Bizer C, Heath T, editors. Proceedings of the Workshop on Linked Data on the Web, LDOW 2016, co-located with 25th International World Wide Web Conference (WWW 2016), Vol. 1593 of CEUR Workshop Proceedings. Aachen, Germany: CEUR-WS.org; 2016 - 25.
Vrijens G. Knowledge graph construction to facilitate chemical compound hazard assessment in the toxin project. [Master’s thesis] School of Engineering and Computer Science - University of Liège. 2023 - 26.
Grüninger M, Fox MS. The Role of Competency Questions in Enterprise Engineering. Boston, MA: Springer US; 1995. pp. 22-31 - 27.
Yamagata Y, Yamada H. Ontological approach to the knowledge systematization of a toxic process and toxic course representation framework for early drug risk management. Scientific Reports. 2020; 10 :14581 - 28.
He Y, Liu Y, Zhao B. OGG: A biological ontology for representing genes and genomes in specific organisms. In: The 2014 International Conference on Biomedical Ontologies (ICBO 2014): October 8-9, 2014; Houston, TX, USA. CEUR Workshop Proceedings. Aachen, Germany: CEUR-WS.org; 2014. pp. 13-20 - 29.
The UniProt Consortium. UniProt: the universal protein knowledgebase in 2021. Nucleic Acids Research. 2021; 49 (D1):D480-D489 - 30.
Matthews L, Gopinath G, Gillespie M, Caudy M, Croft D, de Bono B, et al. Reactome knowledgebase of human biological pathways and processes. Nucleic Acids Research. 2008; 37 :D619-D622 - 31.
Kanehisa M, Furumichi M, Tanabe M, Sato Y, Morishima K. KEGG: new perspectives on genomes, pathways, diseases and drugs. Nucleic Acids Research. 2016; 45 (D1):D353-D361 - 32.
Davis AP, Murphy CG, Saraceni-Richards CA, Rosenstein MC, Wiegers TC, Mattingly CJ. Comparative toxicogenomics database: A knowledgebase and discovery tool for chemical-gene-disease networks. Nucleic Acids Research. 2022; 37 :D786-D792 - 33.
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nature genetics. 2000; 25 :25-29 - 34.
Thomas P, Hill D, Mi H, Osumi-Sutherland D, Auken K, Carbon S, et al. Gene Ontology Causal Activity Modeling (GO-CAM) moves beyond GO annotations to structured descriptions of biological functions and systems. Nature Genetics. 2019; 51 :1429-1433 - 35.
Gustafson E, Debruyne C, De Troyer O, Rogiers V, Vinken M, Vanhaecke T. Screening of Repeated Dose Toxicity Data in Safety Evaluation Reports of Cosmetic Ingredients Issued by the Scientific Committee on Consumer Safety Between 2009 and 2019. Archives of Toxicology. 2020; 94 (11):3723-3735 - 36.
Volz J, Bizer C, Gaedke M, Kobilarov G. Silk - A link discovery framework for the web of data. In: Proceedings of the WWW2009 Workshop on Linked Data on the Web, LDOW 2009, Madrid, Spain, April 20, 2009, Volume 538 of CEUR Workshop Proceedings. Aachen, Germany: CEUR-WS.org; 2009 - 37.
David J, Euzenat J, Scharffe F, Trojahn C. The Alignment API 4.0. Semantic Web. 2011; 2 :3-10 - 38.
Knublauch H, Kontokostas D. Shapes Constraint Language (SHACL). W3C Recommendation. USA: W3C; 2017. Available from: https://www.w3.org/TR/shacl/ - 39.
Mouromtsev D, Pavlov DS, Emelyanov Y, Morozov AV, Razdyakonov DS, Galkin M. The simple web-based tool for visualization and sharing of semantic data and ontologies. In: Villata S, Pan JZ, Dragoni M, editors. Proceedings of the ISWC 2015 Posters & Demonstrations Track co-located with the 14th International Semantic Web Conference (ISWC-2015), Bethlehem, PA, USA, October 11, 2015, Vol. 1486 of CEUR Workshop Proceedings. Aachen, Germany: CEUR-WS.org; 2015 - 40.
Gupta A. Data provenance. In: Liu L, Tamer Özsu M, editors. Encyclopedia of Database Systems. New York, NY: Springer; 2009. p. 608
Notes
- https://ivtd.research.vub.be/irp-non-animal-methodologies-for-toxicity-testing-of-chemical-compouns-toxin-0
- https://health.ec.europa.eu/scientific-committees/scientific-committee-consumer-safety-sccs_en
- Hazard assessment, i.e., evaluating the intrinsic property of a molecule inducing toxicity out of the use context, is the first step of every safety assessment process.
- or a set of these when the knowledge graph is defined by more than one ontology
- The difference between the two is that the former refers to mistakes (e.g. typos) and the latter to domain axioms not being respected (e.g. an instance cannot be an element of two disjoint classes).
- https://www.vegahub.eu/portfolio-types/in-silico-models/
- https://livertox.univie.ac.at/
- http://www.sapredictor.cn/index.php
- https://ice.ntp.niehs.nih.gov/
- https://health.ec.europa.eu/system/files/2021-08/sccs_o_232_0.pdf
- Linked Data is an initiative in which one published RDF data according to specific best practices that result in interconnected data stored on different servers; a Web of data.
- http://geneontology.org
- https://jena.apache.org/documentation/fuseki2/
- http://vowl.visualdataweb.org/webvowl.html