 Open access peer-reviewed chapter
Open access peer-reviewed chapter
Abstract
Hidden Markov Models (HMMs) are the most popular recognition algorithm for pattern recognition. Hidden Markov Models are mathematical representations of the stochastic process, which produces a series of observations based on previously stored data. The statistical approach in HMMs has many benefits, including a robust mathematical foundation, potent learning and decoding techniques, effective sequence handling abilities, and flexible topology for syntax and statistical phonology. The drawbacks stem from the poor model discrimination and irrational assumptions required to build the HMMs theory, specifically the independence of the subsequent feature frames (i.e., input vectors) and the first-order Markov process. The developed algorithms in the HMM-based statistical framework are robust and effective in real-time scenarios. Furthermore, Hidden Markov Models are frequently used in real-world applications to implement gesture recognition and comprehension systems. Every state of the model can only observe one symbol in the Markov chain. In contrast, every state in the topology of a Hidden Markov Model can see one symbol emerging from a particular gesture. The matrix representing the observation probability distribution contains the likelihood of observing a symbol in each state. As an illustration, the probability that a symbol will emit is determined by its observation probability in the first state. In the recognition task, the emission distribution is another name for the observation probability distribution. For the following reasons, HMM states are also referred to as hidden. First, choosing to emit a symbol denotes the second process. Second, an HMM’s emitter only releases the observed symbol. Finally, since the current states are derived from the previous states, the emitting states are unknown. HMMs are well-known and more flexible in the field of gesture recognition because of their stochastic nature.
Keywords
- recognition algorithm
- gesture recognition
- hidden Markov models
- statistical framework
- probability distribution matrix
1. Introduction
One of the greatest methods for pattern recognition is HMM since it can deal with the issues caused by spatiotemporal variability [1, 2, 3, 4]. Additionally, HMMs have been effectively used in the classification of gestures, speech, modeling of proteins, etc. [2, 5, 6, 7, 8]. Because segmentation and recognition are tuned concurrently during recognition using HMMs, the use of HMMs increases the effectiveness of recognition-based segmentation. The two categories of gesture are communicative gestures (also known as key gestures or meaningful gestures) and noncommunicative gestures (i.e., garbage gesture or transition gesture) [9, 10, 11, 12]. In other words, as indicated in Figure 1, a natural gesture comprises three phases: pre-, key-, and post-gesture. The key gesture may be described as a hand trajectory component that has clear human significance. While pre- and post-gestures signify inadvertent motion utilized to integrate important gestures (Figure 1).
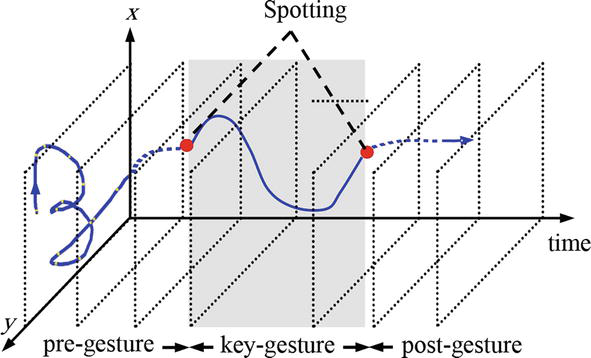
Figure 1.
Three main phases for the trajectory for spotting meaningful gestures.
A method to detect American Sign Language was developed by Vogler and Metaxas [13], using HMMs and three video cameras (ASL). To extract 3D characteristics of the user’s hand and arm, they employed an electromagnetic tracking device. Two trials using 99 texts and 22 signals to test their method were conducted. Both single signals and full phrases were used in the trials. For isolated signs and continuous phrases, their system has obtained recognition rates of 94.5 and 84.5%, respectively. A data collection of 40 signs was used by Starner
A German Sign Language (GSL) recognition system based on HMMs was presented by Bauer and Kraiss [14] and uses colored gloves. Both continuous and isolated indicators have been used to test the system. Subunit HMMs were employed in their system to identify isolated signs and carry out the spotting signs. The system detected spotted hand signals with an accuracy of 92.5% for 100 isolated signs, according to the findings of the experiment.
For French Sign Language (FSL), Braffort [15] presented a recognition method that classified signs into communicative, noncommunicative, and variable signals. In order to extract information like hand position and appearance, a colored glove was utilized. These features were then used to generate HMM codewords. The studies followed classifiers; one was used to identify communicative signs, and the other to identify both noncommunicative and variable indicators. For a repertoire of seven signs, their method achieves a 96% recognition rate.
The approach used by Lee and Kim [6] is regarded as one of the pioneering examples of distinct modeling that deals with transition gestures. Regardless of the hand morphologies, this approach has been utilized to handle 2D hand trajectory (also known as gesture trajectory). The disadvantage of this technique is that while merging two states, the quantity of samples is not taken into account.
The Hierarchical Activity Segmentation (HAS) method was proposed by Kahol
The remainder of the chapter is organized as next. Section 2 explores an overview of the Hidden Markov Model. Section 3 conducts hand gesture recognition application and Section 4 provides the concluding remarks.
2. Hidden Markov model
The most popular method for gesture recognition algorithms is Hidden Markov Models (HMMs) [1, 18, 19, 20]. HMMs are mathematical models of the stochastic process and observations, which should be estimated, using a well-defined approach based on previously stored information. The statistical approach in HMMs has numerous benefits as a strong mathematical framework, effective learning and decoding techniques, the ability to handle sequences well, and flexible topology for the statistical syntax. HMMs are a viable option for modeling dynamic gestures since they are time-varying processes that exhibit statistical variation and are frequently employed in practice to put gesture recognition and comprehension systems into place.
Every state in the Markov chain can only see one symbol, whereas the architecture of HMMs allows for more observation, every state can see one sign emerging from a different gesture. The likelihood of finding a symbol for each state is contained in the observation probability distribution matrix. For instance, the probability of observing a symbol in the state
2.1 Elements of HMMs
HMMs can be expressed with
The group of states
For each state
An
N -by-N transition matrix
where
The potential observations list
T is the gesture path length.The group of symbols
where
An
where
Two model parameters (
Here,
2.2 HMMs problems
Mathematically, three variables govern the application of HMMs. These elements are topologies, the chosen emission features, and the probabilities of their observations. The observation job informs the feature choices. Moreover, there are three primary problems that must be resolved to effectively use transition probabilities in practical applications for real-world applications. They are:
Evaluation problem : How to determine the probability of the observed sequence given the observation sequenceDecoding problem : How to choose the most efficient routeEstimation problem : How to change or update the model
2.2.1 Evaluation problem
The simple way is to calculate
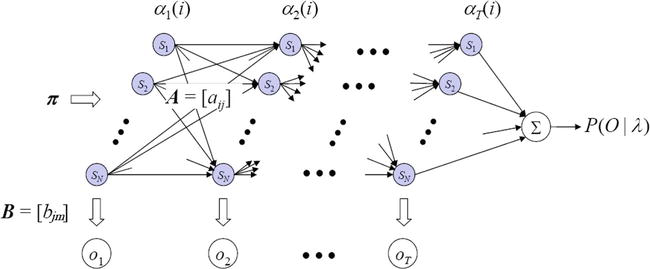
Figure 2.
Forward algorithm for trellis diagram.
Using the following recursive relation, the computation of all forward variables is simple
where the
Therefore, the required probability
The probability of the partial observation sequence is similar
Moreover, compute the recursive relationship
Then,
Hence, for state
This estimate offers a different calculation
Finally, the prior equation is crucial and more precise in predicting the formulas required for gradient-based training.
2.2.2 Decoding issue
To explain the precise state sequence that produces the observations
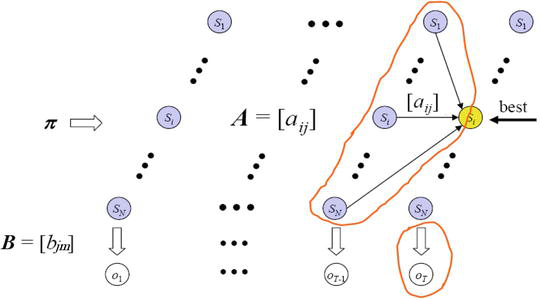
Figure 3.
Forward algorithm for trellis diagram with
The Viterbi path is a set of hidden states. The forward variable
To demonstrate how the Viterbi algorithm works, the following steps are used:
Step1 (Initialization):
(a)
(b)
Step2 (Recursion):
(a)
(b)
Step3 (Termination):
(a)
(b)
Step4 (Reconstruction):
The resulted optimal states sequence and tate optimized likelihood function is
2.2.3 Estimation problem
The system’s effectiveness is greatly impacted by the training procedure. A HMM is trained by modifying its model parameters to get the best description for the observation sequence
To demonstrate how the BW algorithm works, two auxiliary variables are defined. The probability of traveling along an arc
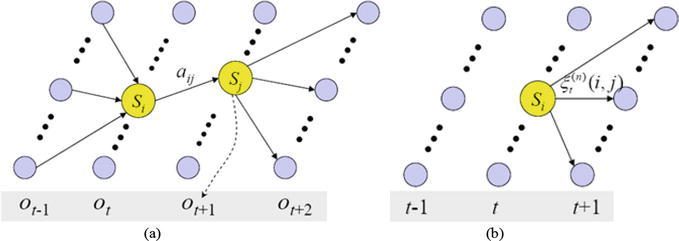
Figure 4.
Trellis diagram learning method according to Baum-Welch. (a) the likelihood of making the journey from state
where the transition probability is representing by
However, by using forward and backward variables, Eq. (18) becomes:
The second variable (state probability is defined by;
where
Therefore, the relationship between
As a result, BW algorithm modifies the new HMM parameters to have the highest likelihood under the condition
where
2.3 Topologies of HMMs
Because it depends on the training data that is available and the intended model to represent, HMMs topology has a considerable impact on the success of the recognition process. There are three types of HMMs: (1) Fully connected models have positive
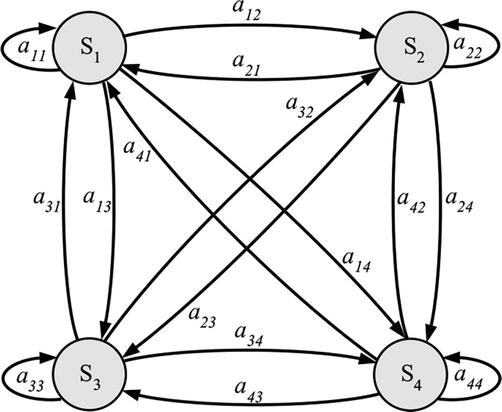
Figure 5.
Ergodic model with four states.
Therefore, the transition among states has become:
(2) [18] for the Left–Right model or the Bakis model. According to Figure 6, each state of this model can either proceed to itself or one of the following states. The state transition coefficients of this model have the feature that, for a
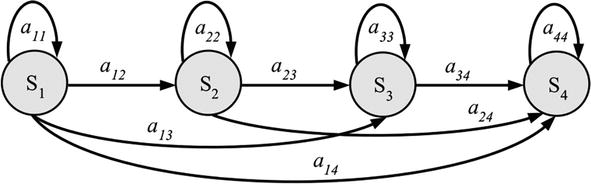
Figure 6.
Left–right model with four states.
Moreover, the model’s starting state probabilities possess the characteristic;
where the state sequence must begin from
The transition coefficients, specifically for the final state in a left–right model, are described as follows using the laws of probability:
(3) The Left–Right Banded model (LRB) is shown in (7) [21]. The LRB model arranges the states from left to right, and each one has a positive probability of returning to either itself or the one after it. The model’s state transition coefficients exhibit the characteristic;
Therefore, in an LRB model, the last state’s and other states’ state transition coefficients are as follows:
and any HMM parameter with a zero initial value stays zero throughout the estimate procedure. The Left–Right Banded model will thus have a detrimental impact on the process (Figure 7).
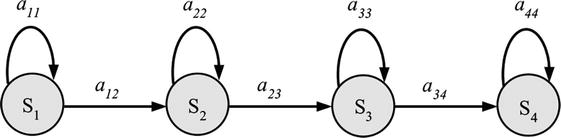
Figure 7.
Left–right banded model with four states.
3. Conducting hand gesture recognition application
A gesture is a spatiotemporal pattern that might be static, dynamic, or both.1 The term “spatio” refers to locating the hand motion in each frame. To be temporal means to know when a gesture begins and ends. By comparing the identified hand correspondences between subsequent frames, the hand gesture path is determined (Figure 8). It goes without saying that choosing effective features to identify the hand gesture path has a big impact on how well a system performs. The combined features of location, orientation, and velocity with respect to Cartesian systems are used to enhance recognition rates. The HMM codewords are then clustered using K-means. Hand segmentation and feature extraction in computer vision are important steps in developing vision-based hand gesture recognition systems and classification methods for practical applications. Each isolated gesture in our experimental results was based on 60 video sequences, of which 42 were used to train the Baum-Welch algorithm and 18 to test it (i.e., in total, there are 1512 video samples in our database, of which 648 are used for testing). To place a gesture in the appropriate category, the gesture recognition module compares the hand gesture path to a database of reference gestures. The Viterbi algorithm has calculated the greater priority to recognize numbers frame by frame (Figure 9). Our application demonstrated good results to identify isolated integers in real-time implementation. The training and testing procedures are covered in the following subsections.
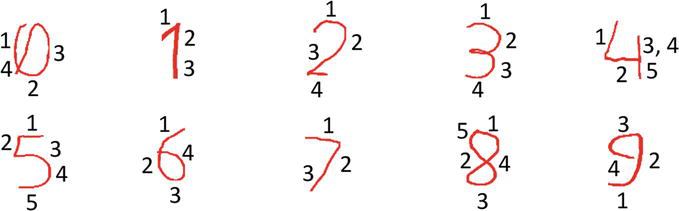
Figure 8.
Hand gesture paths of numbers (0–9) with respect to their segmented parts.
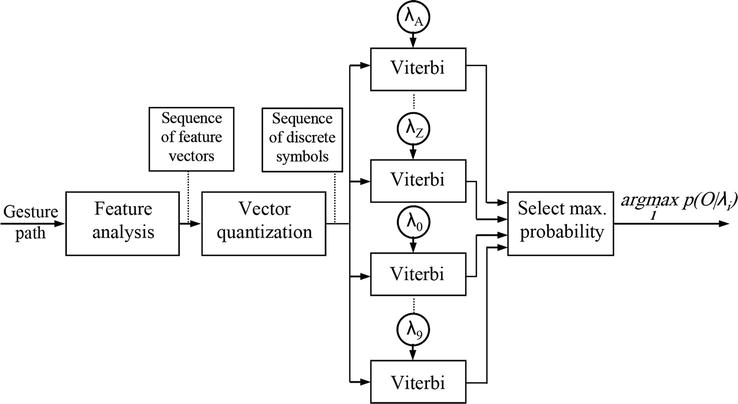
Figure 9.
Block representation of a meaningful gesture recognized by HMMs (Viterbi).
3.1 Model training
The Baum-Welch technique is essential to the proposed system for classifying gestures since it is utilized to train the initialized HMMs parameters
3.1.1 Model size
The size of the HMMs must be chosen before the HMMs training process begins. We need how many states, exactly? The complexity of the numerous patterns that will be distinguished by HMMs must be taken into account when estimating the number of states. In other words, when we displayed the graphical pattern, the number of segmented portions was taken into account. The over-fitting2 issue arises when there are insufficient training data samples and excessive state numbers are used.
Additionally, using too few states reduces the discrimination capability of HMMs since several segmented parts of a graphical pattern are modeled using the same state. Our gesture recognition method maps each straight-line segment into a single HMM state, which establishes the number of states (Figure 10). We must examine potential patterns to determine how many distinct segments are contained in each pattern in order to represent different graphical patterns. It could be a good idea to employ varying numbers of states in the various HMMs, which were once used to represent various kinds of patterns. For instance, only two states are necessary to represent a graphical pattern “L,” whereas six states are needed to represent a graphical pattern “E,” and four states are needed to represent a graphical pattern “3.”
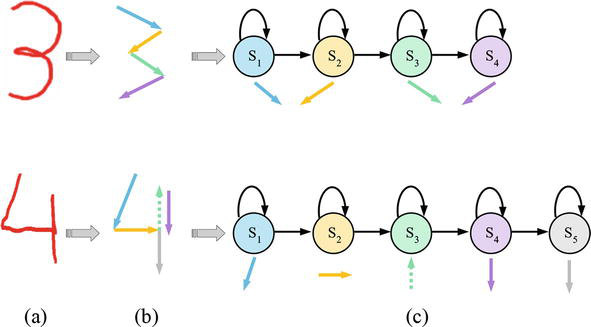
Figure 10.
HMM topologies with a straight-line segment (a) the gesture number derived from the hand motion trajectory (b) the gesture number’s line segment (c) LRB model with segmented line codewords.
3.1.2 Initializing a left: Right banded model
The initial values of each parameter in the HMMs must be set before beginning the iterative Baum-Welch process. The initial model must somehow indicate how we want to represent various model states, and this is the only general need. Nevertheless, depending on the HMMs, this condition has a variety of effects. In reality, the LRB model is taken into account because each state in ergodic topology has more transitions than LR and LRB topologies, making it easy to lose structure data. In contrast, because the LRB topology excludes a backward transition, the state index either rise over time or stays constant. LRB topology is also simpler for training data than LR topology and more constrained, allowing for data-to-model matching [21].
It seems intuitive that a proper initialization of the HMMs
It is possible to select the transition matrix’s diagonal elements
and
Such that
This is adequate for an automatic training method where state 1 is intended to represent the first part of the training data, state 2 the second part, etc. As a result, the same parameters can be used to initialize all output probability distributions for various states. As a result, the training data are used to determine more accurate output probability parameters for each state in the first iteration of the Baum-Welch algorithm. Due to the discrete nature of HMM states, all members of matrix
where
The state can return on its own or merely to the next closest state for each new time sample. Consequently, the
This will guarantee that we begin from the initial state.
3.1.3 Termination of HMMs learning
The Baum-Welch training algorithm is quite effective. After 5–10 iterations, a satisfactory model is frequently found. The trained model must be flexible enough to faithfully represent an entirely new test sequence after training. The training procedure is repeated until the transition and emission matrices change. If the change is smaller than 0.001, that is, tolerance
The primary purpose of tolerance is to reduce the number of steps the Baum-Welch algorithm needs to take to successfully complete a task. The process is stopped if any one of the next three quantities falls below the tolerance limit. First, a current observation sequence’s log-likelihood (
Keep in mind that the Baum-Welch algorithm required fewer steps to run before terminating as the level of tolerance increased. In actuality, the maximum number of iterations regulates the maximum number of algorithm execution steps. The termination occurs with a warning if the Baum-Welch algorithm runs for 500 iterations before reaching the chosen tolerance value. If this happens, the algorithm should be allowed to run for a greater maximum number of iterations until it meets the specified tolerance before terminating. The provision of enough training data is typically exceedingly challenging. Because of this, some observations may never occur in the tiny collection of training data, even if we may be aware that they may have happened with some small probability. When a discrete HMM is trained on such data, Baum-Welch will assign a
3.2 Model testing
The process of classification greatly benefits from the selection of the best HMM topology. The goal of the work is to create HMM topologies with a variety of state numbers in order to select the topology that will produce the best outcomes for an isolated gesture system. An extracted discrete vector features from image sequences are subjected to the application of HMMs with Left–Right Banded (LRB), Left–Right (LR), and Ergodic topologies. These topologies are taken into consideration with a variety of states ranging from 3 to 10. Our gesture recognition system uses the complexity of each gesture number to calculate the number of states by mapping each straight-line segment into a single HMMs state (Figures 8 and 10). For two reasons, the number of states is a significant parameter. First, the over-fitting issue is caused by the use of excessive state numbers when there are not enough training data samples. Second, having too few states reduces the discrimination capacity of HMMs since multiple segmented parts of a graphical pattern are modeled on a single state.
In practice, the LRB model with five states is really used in the gesture recognition system in order to guarantee that all of the states are used. The structure data is easily lost in Ergodic topology since each state has more transitions than in LR and LRB topologies. Completely contrary, the LRB topology avoids a backward transition in which the state index either increases or stays as time goes on. LRB topology is also easier to train on data than LR topology and more constrained in its ability to match data to the model. Additionally, the gesture paths “4” and “5” have the most segmented sections, so using 5 states is taken into consideration to make sure all of these parts are utilized. The recognition ratio is the number of recognized gestures correctly to the number of tested gestures (Eq. (41)).
The BW method is used to train the HMM topologies and the Viterbi algorithm is used to test them. From Figure 11, the LRB performs the best performance, with an average ratio of 97.78% for states ranging from 3 to 10. Additionally, topologies with 4 states in LR and LRB received the greatest recognition. Additionally, compared to LR and Ergodic topologies, LRB topology is always superior. In Figure 11, there is not a significant difference between LRB and LR in terms of outcomes, and the results of the ergodic topology were subpar in comparison to those of LRB and LR topologies. LRB topology with a number of states equal to 5 is typically the best in terms of its impact on gesture recognition in empirical studies.
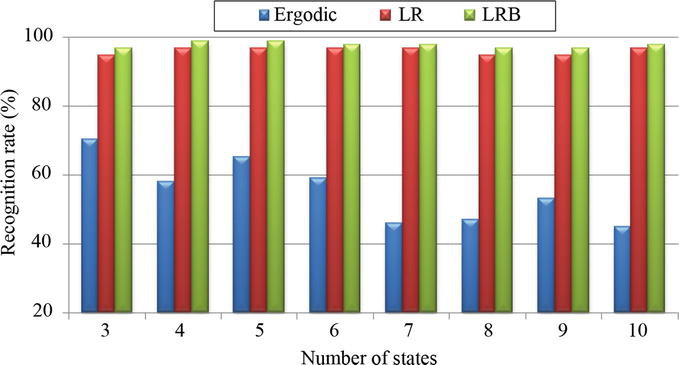
Figure 11.
Results of isolated gesture recognition for three HMMs topologies using states ranging from 3 to 10.
4. Conclusions
The foundational Hidden Markov Model method was discussed in this chapter. HMMs are generative models that put a strong emphasis on modeling the observation in order to compute the conditional probability and specify the joint probability distribution in order to resolve a conditional problem. This study assists in determining the best HMM topology and classification method in terms of outcomes. Furthermore, an application was made on recognizing the gesture of the hand for Arabic numbers from 0 to 9 using the classifier of HMMs in terms of their impact on gesture recognition. In addition, studies and research have been conducted on the effects of HMMs with ergodic, left–right, and left–right banded topologies, as well as varying numbers of states ranging from 3 to 10, on hand gesture recognition. It is concluded that there is not a significant difference between LRB and LR in terms of results and that Ergodic topology performed poorly in comparison to LRB and LR topologies. LRB topology with a total of 5 states is typically the best in terms of its effect on gesture recognition.
Abbreviations
| HMMs | Hidden Markov Models |
| ASL | American Sign Language |
| GSL | German Sign Language |
| FSL | French Sign Language |
| HAS | Hierarchical Activity Segmentation |
| cHMMs | coupled HMMs |
| BW | Baum-Welch algorithm |
| LR | Left–Right model |
| LRB | Left–Right Banded model |
References
- 1.
Rabiner L. A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE. 1989; 77 (2):257-286 - 2.
Wang L, Hasegawa-Johnson M. A DNN-HMM-DNN hybrid model for discovering word-like units from spoken captions and image regions. Interspeech. 2020:1456-1460. DOI: 10.21437/interspeech.2020-1148 - 3.
Wang N, Wang L, Sun Y, Kang H, Zhang D. Three-module modeling for end-to-end spoken language understanding using pre-trained DNN-HMM-based acoustic-phonetic model. Interspeech. 2021:4718-4722. DOI: 10.21437/interspeech.2021-501 - 4.
Amoolya G, Hans A, Lakkavalli V, Durai S. Automatic speech recognition for Tulu language using Gmm-hmm and DNN-HMM techniques. In: 2022 International Conference on Advanced Computing Technologies and Applications (ICACTA). Coimbatore, India: IEEE; 2022. DOI: 10.1109/ICACTA54488.2022.9753319 - 5.
Starner T, Weaver J, Pentland A. Real-time American sign language recognition using desk and wearable computer based video. IEEE Transaction on Pattern Analysis and Machine Intelligence. 1998; 20 (12):1371-1375 - 6.
Lee H, Kim J. An HMM-based threshold model approach for gesture recognition. IEEE Transaction on Pattern Analysis and Machine Intelligence. 1999; 21 (10):961-973 - 7.
Gao W, Fang G, Zhao D, Chen Y. Transition movement models for large vocabulary continuous sign language recognition. In: IEEE International Conference on Automatic Face and Gesture Recognition. Seoul, Korea (South): IEEE; 2004. pp. 553-558 - 8.
Yang J, Pan J, Li J. sEMG-based continuous hand gesture recognition using GMM-HMM and threshold model. In: 2017 IEEE International Conference on Robotics and Biomimetics (ROBIO). Macau, Macao: IEEE; 2017. DOI: 10.1109/ROBIO.2017.8324631 - 9.
Yang H, Park A, Lee S. Gesture spotting and Recognitiomn for human-robot interaction. IEEE Transaction on Robotics. 2007; 23 (2):256-270 - 10.
Kahol X. Gesture segmentation in complex motion sequences. [Master’s thesis] Arizone State University, Tempe, AZ. 2003 - 11.
Elmezain M, Alwateer M, El-Agamy R, Atlam E, Ibrahim H. Forward hand gesture spotting and prediction using HMM-DNN model. Informatics. 2022; 10 :1. DOI: 10.3390/informatics10010001 - 12.
Nguyen N, Phan T, Kim S, Yang H, Lee G. 3D skeletal joints-based hand gesture spotting and classification. Applied Sciences. 2021; 11 :4689. DOI: 10.3390/app11104689 - 13.
Vogler C, Metaxas D. A framework for recognizing the simultaneous aspects of American sign language. Journal of Computer Vision and Image Understanding. 2001; 81 (3):358-384 - 14.
Bauer B, Kraiss K. Video-based sign recognition using self-organizing subunits. In: International Conference on Pattern Recognition. Quebec City, QC, Canada: IEEE; 2002. pp. 434-437 - 15.
Braffort A. ARGo: An architecture for sign language recognition and interpretation. In: International Gesture Workshop Progress in Gestural Interaction. London: IEEE, Springer; 1996. pp. 17-30 - 16.
Kahol K, Tripath P, Panchanthan S. Automated gesture segmentation from dance sequences. In: IEEE International Conference on Automatic Face and Gesture Recognition. Seoul, Korea (South): IEEE; 2004. pp. 883-888 - 17.
Kahol K, Tripath P, Panchanthan S. Documenting motion sequences: Development of a personalized annotation system. IEEE Multimedia Magazine. 2006; 13 (1):35-47 - 18.
Huang X, Ariki Y, Jack M. Hidden Markov Models for Speech Recognition. Taylor & Francis, Ltd.; 1990. DOI: 10.2307/1268779 - 19.
Elmezain M, Al-Hamadi A, Krell G, El-Etriby S, Michaelis B. Gesture recognition for alphabets from hand motion trajectory using hidden Markov models. In: IEEE International Symposium on Signal Processing and Information Technology. Giza, Egypt: IEEE; 2007. pp. 1192-1197 - 20.
Elmezain M, Al-Hamadi A, Appenrodt J, Michaelis B. A hidden Markov model-based isolated and meaningful hand gesture recognition. International Journal of Electrical, Computer, and Systems Engineering. Academia education; 2009; 3 (3):156-163 2070-3813 - 21.
Elmezain M, Al-Hamadi A, Michaelis B. Real-time capable system for hand gesture recognition using hidden Markov models in stereo color image sequences. Journal of WSCG. 2008; 16 (1) ISSN: 1213-6972:65-72 - 22.
Elmezain M, Al-Hamadi A, Appenrodt J, Michaelis B. A hidden Markov model-based isolated and meaningful hand gesture recognition. In: International Conference on Computer Vision, Image and Signal Processing, PWASET. Vol. 31. Academia.edu; 2008. pp. 394-401 - 23.
Elmezain M, Al-Hamadi A, Appenrodt J, Michaelis B. A hidden Markov model-based continuous gesture recognition system for hand motion trajectory. In: International Conference on Pattern Recognition. Tampa, FL, USA: IEEE; 2008. pp. 519-522 - 24.
Baum L, Petrie T, Soules G, Weiss N. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. The Annals of Mathematical Statistics. 1970; 41 (1):164-171 - 25.
Soriano M, Huovinen S, Martinkauppi B, Laaksonen M. Skin detection in video under changing illumination conditions. In: Proceeding International Conference on Pattern Recognition. Barcelona, Spain: IEEE; 2000. pp. 839-842 - 26.
Tetko I, Livingstone D, Luik A. Neural network studies. 1. Comparison of overfitting and overtraining. Journal of Chemical Information and Computer Sciences. 1995; 35 :826-833
Notes
- Gestures are hand motions, while postures are static morphs of the hands.
- When HMMs describe random error rather than the underlying relationship, over-fitting takes place. Potential over-fitting issues depend not only on the quantity and quality of data and parameters, but also on how well the model structure fits with the degree of model error and the nature of the data. When more training does not improve generalization, additional strategies such as regularization, early stopping, cross-validation, and others are utilized to prevent the issue of over-fitting. The reader can seek for additional information with [26].