Open Access is an initiative that aims to make scientific research freely available to all. To date our community has made over 100 million downloads. It’s based on principles of collaboration, unobstructed discovery, and, most importantly, scientific progression. As PhD students, we found it difficult to access the research we needed, so we decided to create a new Open Access publisher that levels the playing field for scientists across the world. How? By making research easy to access, and puts the academic needs of the researchers before the business interests of publishers.
We are a community of more than 103,000 authors and editors from 3,291 institutions spanning 160 countries, including Nobel Prize winners and some of the world’s most-cited researchers. Publishing on IntechOpen allows authors to earn citations and find new collaborators, meaning more people see your work not only from your own field of study, but from other related fields too.
To purchase hard copies of this book, please contact the representative in India:
CBS Publishers & Distributors Pvt. Ltd.
www.cbspd.com
|
customercare@cbspd.com
A Markov model describes a randomly varying system that satisfies the Markov property. This means that future and past states at any time are independent of the current state. The two most commonly used types of Markov models are Markov chains and higher-order Markov chains. Therefore, three types of Markov models are proposed in this chapter of the book: (i) supply chain management, (ii) Markov queue waiting time monitoring, and (iii) Markov fuzzy time series forecasting. The introduction introduces Markov chain (MC) and summarizes the most important aspects of Markov chain analysis. The first model explores a Markov queue model coupled to a storage system using the classical (0, Q) policy. The second model focuses on the M/M/1/N service mode and develops a control chart for an Ms/Ms/1/N type simulated queue to monitor customer waiting times. The third is a higher-order Markov model (HOMM), which uses fuzzy sets to predict future states based on given hypothetical time series data. Numerical calculations are designed to find optimal order quantities, monitor customer wait times, and predict future HOMM conditions.
Statistics Department, University of Botswana, Gaborone, Botswana
Wilford B. Molefe
Statistics Department, University of Botswana, Gaborone, Botswana
*Address all correspondence to: sivasamyr@ub.ac.bw
1. Introduction
The term probability refers to the proportion of interesting events observed in one or more random experiments. The probability of an event A occurring in an experiment is given by the ratio f/T, where f = A can occur and T = the total number of possible outcomes of this experiment. We denote the set of all outcomes of a random experiment by Ω = {ω}, which is called the sample space. A real-valued function X = X(ω) that gives a unique real value for each term “ω” in the real set R (= (−∞, ∞)) is called a (real valued) random variable. We classify a random variable as discrete if it has only a few specific values, such as −1, 3, 8, and 17. Otherwise, it is classified as continuous. A family of random variables indexed by time “t” defined on a state space S i.e., X=Xt∈S:t∈T=0∞ is called a stochastic process. Thus, a typical Stochastic process is indexed by time “t” and takes its state values over a space S is represented as
X=Xωt∈Sω∈Ωt∈TE1
1.1 Continuous time (CT) Markov process (MP) {X(t), t > 0}
If the probability of future state of X(t) depends only on the present but not on the past states then {X(t), t > 0} is a MP for any set of time points t1<t2<⋯<tn+1 and any set of states x1<x2<⋯<xn+1⇒
A discrete time MP {Xt = Xn: n = 0,1 2,…} is called a Markov chain (MC). Let the conditional probability of moving from state i to state j be Pij = P(X(n + 1) = j | Xn = i), n ≥ 0 and i, and j = 0,1,2,….
Define one step transition probability matrix (TPM): P=Pij Let Pijm=. The conditional probability of moving to state j starting from state i in m steps which can be calculated using the Chapman Kolmogorov (CK) equations:
Pijm=PrXm=jX0=i=∑k=0∞PikrPkjm−rE3
fori,j=0,1,2,…andm≥r≥0.E4
Thus, the mth step TPM is Pm=Pijm.
A MC is completely determined if the initial distribution P(X0 = j) and its one step TPM P are all known or estimated by conducting a sample survey.
1.3 Classification of States of a MC
State j is accessible from state i if there exists an integer m such that Pijm>0.
Two states i and j communicate with each other if both are accessible from each other.
The TPM of an MC defined on a state space S is said to be irreducible if all states communicate with each other state in S.
State i is recurrent if the system will return to it after some finite time in the future.
If a state is not recurrent, it is transient.
A state is periodic if it can only return to itself after a fixed number of transitions greater than 1 (or multiple of a fixed number).
A state that is not periodic is aperiodic.
An absorbing state is one that locks in the system once it enters.
All states belonging to a class are either recurrent or all transient and may be either all periodic or aperiodic.
1.4 Stationary distribution of an aperiodic and irreducible MC
Let and
πj=limn→∞PijnandΠ=π0π1π2…,∑j=0∞πj=1.E5
Under certain conditions, these limiting probabilities πj can be shown to exist and are independent of the starting state i.
They represent the long run proportions of time that the process spends in each state j. Also πj = the steady-state probability that the process will be found in each state j. Computation of the row vector Π:
ΠP=Π,∑j=0∞πj=1.E6
For an aperiodic and recurrent MC on the state space Ω = {1, 2,…,m}. Let πj=limn→∞Pijn, ∑j=0mπj=1 and row vector Π = (π0, π1,…, πm).
Then, the stationary probability vector Π satisfies the following set of simultaneous equations:
ΠP=Π,Π1=1=∑j=0mπjE7
Computational Hint: One of the m equations of ΠP=Π is redundant. It is advised that replacing any of the equations of Π P = Π by Π 1 = 1, we form a set of m simultaneous equations which yield the unique Π. One can find quite a number of applications of finite state MCs in our social life activities.
1.5 Generator Matrix of a continuous time MP
Let Tij denote the time for the MP to go from state i to state j and qij be the known rate of transition from state i to state j.
Then Tij→eqij. Let qi = ∑j ≠ iqij,
The infinitesimal generator is
Q=−q0q01q02q03…q10−q2q12q13…q20q21−q3q23…⋮⋮⋮⋮⋮E8
The stationary distribution is obtained by solving the system of equations
ΠQ=0,Π1=1=∑n=0∞πE9
Basic information on MC definition, classification of states, etc. can be found in [1, 2]. Instructions for calculating the state characteristics of different types of MCs using software “markov chains” are briefly discussed in [3].
1.6 Ordering Markov models discussed
Section 2 considers customer arrivals to demand a single product of supply chain management. All arrivals join an M/M/1/N/FCFS system attached to a storage house under the classical (0, Q) policy. The joint process of limiting queue length and the inventory level is denoted by Z = {(L, J)} = limt → ∞{(L(t), J(t))}. We then obtain stationary probability vector of the Z process. A cost function is formed as an implicit function of the order quantity Q and other input values, and the optimal order quantity that minimizes its total cost is determined.
Section 3 presents the analysis on an M/M/1/N queue and develops simulated queue Ms/Ms/1/N. The steady state characteristics such as the embedded queue length and waiting times at all successive transition epochs of the Ms/Ms/1/N system are obtained and a control chart is constructed to monitor the impacts of the customer’s waiting time distribution.
Section 4 introduces a HOMM for analyzing a fuzzy time series as a data sequence. The main focus is to build a first-order MC (FOMC) and another second-order MC (SOMC) for the same data sequence under study. The prediction error (PE) is calculated for both FOMC and SOMC and a comparison is made to isolate the best performer. Section 5 provides a formal concluding report.
A Markov chain sequence can be thought of as a stochastic model. Such a model involves mathematical considerations to estimate the probability of a sequence of future states based on the most recent event rather than past history. The Markov model is a stochastic method for randomly varying systems with the Markov property. This means that at any moment the next state depends only on the current state and is independent of the past.
Markov analysis is a method for predicting the value of a variable whose predicted value is affected only by its current state and not by any past activity. Basically, it predicts a random variable based only on current conditions. The three simple forms of Markov models are (i) MC, (ii) Markov decision process (MDP), and (iii) HOMM. Each model has applications in queuing theory, inventory systems, and reliability theory.
To learn the analysis of queuing problems, researchers can read [1, 2, 4, 5, 6, 7, 8, 9]. Regarding stochastic model building using queuing storage systems, you can refer to [8, 10, 11, 12]. The use of matrix analysis to find steady state results for queue-length processes is well covered in the book by [13].
2.1 Markov decision processes of a supply chain
Supply chain (SC) is a system that links sales branches into a supply chain that would financially improve customer satisfaction and loyalty. Several SC researchers have used integrated queues with inventory policies to reduce lead time and inventory costs.
This section discusses a Markov model that tracks inventory levels in a warehouse connected to a queuing system that sells individual products based on customer demand. This is called the Queue inventory model (QIM), which allows demands to be made during the inventory period. However, those customers who arrive when the warehouse is empty will not be processed until after the ordered products arrive.
The proposed SC facility delivers either a package of Q > 0 fixed-size items for the normal order or only one item for an emergency order to a warehouse that processes customer requirements through a Markov service node M/M/1/N.
Denoting the number of customer demands occurred at time “t” by X(t) and the present on-hand inventory level by Y(t), we propose matrix methods to study the bi-variate stochastic process Z(t) = (X(t), Y(t)) defined on the state space E = N0xQ0 where N0 = 0, 1, 2, …, N and Q0 = 0, 1, 2, …, Q. The system has a single server who admits a maximum number “N” of customers and does not admit those customers who arrive at instances when X(t) = N called lost customers. The queue discipline is on a first-come, first-served basis (FCFS).
Customers requesting one unit of stock arrive at a node of a Poisson process with mean parameter (λ) when X(t) = n, nge0. For each request, after an exponential service time, one product unit is offered with a state-dependent parameter μn. Here we have two types of inventory ordering policies called “regular” and “emergency”:
The normal ordering is the classical (0, Q(>1)) policy, which is set whenever the MDP Z(t) moves from (n,0) to (n + 1,1) n ≥ 1. The lead time is assumed to be an exponentially and identically distributed random variable with rate parameter γ.
The emergency ordering type is the classical (0, Q(=1)), which triggers an order for one product whenever the Z(t) process moves from (1,1) to (0,0). It is assumed that the emergency fulfillment time is a small interval of unit length (IUL) and the urgent order is replenished at a rate of “1.” This emergency order period expires at the end of the IUL. In this particular period, P[(0,0) → (0,1)] = 1/(λ + 1), P[(0,0) → (1,0)] = λ/(λ + 1), that is, whether the replenishment of one product or the arrival of a customer demand is unavoidable.
Our M/M/1/N service system will not accept every incoming customer if there are N customers in front of the system. There can be at most one pending order where “0” is the order point and the order quantity is at most Q units per replenishment for the normal type and only one product for the emergency type.
Due to the properties of exponential distributions and the mixed-type of normal and emergency practices, the proposed sequence Z(t) forms an aperiodic and positive recurrent Markov decision process (MDP). The set properties of the Z system can be easily checked at each stage of service completion. Our main objective is to use a linear function of expected total cost to determine the optimal order quantity and order patterns.
2.2 Generator matrix of the MDP process Z
It is interesting to note that the MDP process Z is also a level-dependent quasi-birth-and-death (LDQBD) in continuous time. We have the (N + 1) level Ln such that ⋃n=0NLn=E. The infinitesimal generator matrix G has the tri-diagonal structure and each submatrix of G is a square matrix of order (Q + 1):
Each sub-matrix of the G is a square matrix of order (Q + 1) indexed by j = 0, 1, …, Q. The precise structures of B = (bi j), A0=aij0,A1=aij1), and A2=aij2 are now described:
The solution of matrix equations generated by level-dependent QBD processes has been widely studied by several researchers, see [6]. A useful matrix analysis method for computing the steady-state probability distributions of the queue-length process of QBDs is presented in Ref. [13].
Distribution: Denote by П = (π0,π1,π2, …., πN), the steady state distribution of Z and by πn the row vector πn = (π(n, 0), …, π(n, Q)) associated with level Ln, n∈N0. Let e = (1,1, …,1) be a column vector of unit elements.
We now discuss a simple linear level reduction method in two phases for a positive recurrent case that leads to computation of the limiting distribution П: Phase 1: Iteratively reduce the state space from the level “N” by removing one level at each step until we reach the level “0” and check if the generator of the level “0” corresponds to a Markov process.
Compute, the U(n) matrices and the rate matrices Rn in terms of the sub-matrices of the generator G:
UN=A1N+A0,E15
Un=A1n−A0Un+1−1A2n+1forn=N−1,N−2,…,1E16
U0=B−A0U1−1A21E17
Rn=−A0Un−1,n=1,2,…,NE18
For 1 ≤ n ≤ N, the matrix U(n) records the transition rate from level Ln to Ln before a visit to L(n − 1). In addition, the matrix −Un−1A2n records the first passage time probabilities from level Ln to Ln (Figure 1).
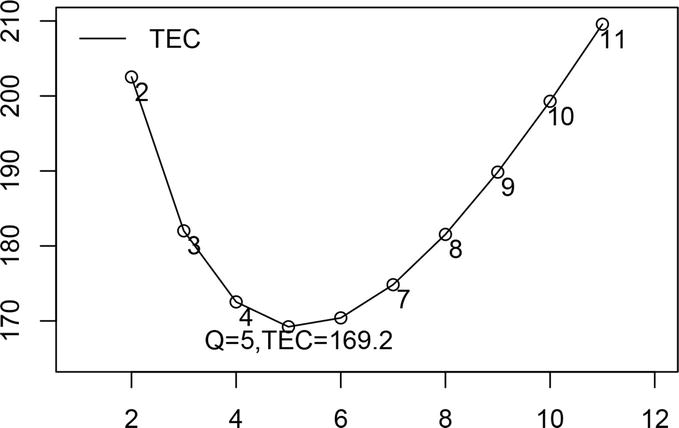
Figure 1.
Q versus TEC.
Phase 2:
Theorem 1.1 The unique stationary joint distribution vector П of the Queue length and the inventory level of the Z = (X, Y) process is given by
πn=πn−1Rnforn=1,2,…,NandΠe=1.E19
2.3 Alternative way of computing the stationary probability vector П
Phase I: Compute.
C0=B,Ci=A1i+A2i−Ci−1−1A0fori=1,2,…,N−1,andE20
CN=A1N+A0+A2N−CN−1−1A0E21
It is noticed that the matrix −Ci−1A0 records the first passage probabilities from level L(i) to L(i + 1).
Phase II: The Stationary probability vector Π=Π0Π1Π2…ΠN,Σn=0NΠne=1 is determined by
ΠNCN=0,E22
Πn=Πn+1A2n+1−Cn−1forn=N‐1,N‐2,…,3,2,1and0E23
2.4 Useful metrics derived from П
The marginal distribution, say Пx, of the queue length process X and that of the inventory process, say Пy are now obtained from the joint probability vector П respectively by Пx = (x0, x1,…, xN) where xn = πne, for n = 0,1,…, N and Пy = (y0, y1, …, yQ) where (yj=Σn=0Nπnj for j = 0, 1, …,Q.
Mean system Size L and Mean wait W¯: The mean system size L and the mean sojourn time W¯ of the queue length process X are given by
L=∑n=0NnπnandW¯=Lλeff,λeff=λ1−πNE24
Mean Inventory Size V¯ and Mean Reorder Rate R¯: The mean inventory size V¯ and the mean reorder rate R¯ of the inventory level process Y are given by
V¯=∑j=0QjyjandR¯=μπ11+∑n=2Nμπn1E25
Total expected cost (TEC) Let us consider three different costs i.e., h = holding cost per item per unit of time, c1 = ordering cost per order and c2 = waiting time cost per unit of time. A linear TEC function is then designed to determine an optimum order quantity Q∗ for which TEC(Q∗) is the minimum:
TEC=hV¯+c1R¯+c2W¯E26
2.5 Determination of optimum order quantity, Q∗, N = 25
A numerical representation is now considered to determine the optimal order quantity that minimizes the TEC described in (14). We set the input dataset as follows: N = 25, arrival rate λ = 2.2, service amount μ = 2.5 and replenishment rate ν = 2.25, and holding cost h = $ 27.5 order price c1 = $ 8.4, and waiting time costs c2 = $ 12.
In this case, the TEC values for varying order quantity Q are calculated with values 2 to 11, and the same is shown graphically in Figure 1. The order quantity that minimizes TEC is Q∗ = 5 and the corresponding price is $ 169.2.
3. Markov modeling of queues with finite capacity: M/M/1/N
The chapter considers a simple simulated Markov model of a single server M/M/1/N. It focuses on a process control method that can monitor customer waiting times. Any service counter with a buffer of waiting customers naturally leads to a limited queue.
3.1 Simulation of cumulative arrival and departure epochs
The formal simulation method is now carried out to fit the M/M/1/N model, and the result is called the simulated Markov model Ms/Ms/1/N. Let the arrival rate of the M/M/1/N exponential population under investigation be λ and the service level be μ. We take enough samples from each exponential population to simulate consecutive customer arrival and departure periods, the cumulative arrival times, the number of customers in such periods, and the waiting time of each customer for a given number of arrivals such as M = 1000. The simulation process algorithm:
Step 1: Simulate “M” number of inter-arrival times {a1, a2, …, aM} from the exponential distribution with parameter λ. Let the starting time of the simulation process be zero, i.e., T0 = 0. Then calculate the sequence of cumulative arrival times Tj = T(j − 1) + aj for j = 1, 2, …, M.
Step 2: Simulate “M” number of service times {s1, s2, …, sM} from the exponential distribution with parameter μ. Then calculate the sequence of service start time times {Sj} and the sequence of departure epochs {Dj}: S1 = (T1), D1 = S1 + s1.
Sj=MaxTjDj}andDj=Sj+sjforj=2,3,…,M.
The waiting time Wj in the system for the jth arrival is then given by Wj = Dj-Tj.
Step 3: The (pre-arrival) number Lja− of customers present at the arrival points {Tj} and post-departure number Ljd of customers present at the departure points {Dj} are then calculated using appropriate formulae during the simulation period.
Step 4: If the maximum value of the sequence Lja−:j=12…M is N-1, then the maximum capacity of the simulated Markov model is Ms/Ms/1/N. For cross checking, verify the fact that the maximum value of the sequence Ljd:j=12…M also equals to N-1.
Step 5: Let fk = Number of times the event Lja−=k occurred for k = 0, 1, …, (N-1) over the arrival epochs {Tj} for j = 1, 2, …, M. Then Σk=0N−1fk=M Thus, the prearrival epoch queue length distribution is given by πka−=fkM..
Step 6: Let Fk = Number of times the event Ljd=k occurred for k = 0, 1, …, (N-1) over the departure epochs {Dj} for j = 1, 2, …, M, where Σk=0N−1Fk=M. Thus, the departure epoch queue length distribution is given by πkd=FkM. For a cross-checking, verify the fact that fk = Fk for k = 0, 1, 2, …, (N-1).
3.2 How to fit M/M/1/N
The special feature is that the maximum number “N” of the simulated version Ms/Ms/1/N plays a crucial role. Let us denote the estimated results obtained from the above simulated outcomes for pre-arrival epoch queue length probabilities by πja− and post-departure epoch probabilities by πjd. Then it can be shown that
πja−=πjd;j∈Sa−=012…N−1=SdE27
Let t0a=0tna be the sequence of times at which Ytna represents the queue length immediately after the nth arrival epoch tna on the state space Sa=12…N. Let, πja=PYna=j:
πj+1a=πja−;j∈Sa−E28
Embedded queue length (EQL) process Y=Yn∈S=012…N: Let us now describe the embedded queue length Yn found at the nth transition epoch tn. Thus, tn represents the nth order statistics of the union of tna∪tnd. Let πj = P()Yn = j) for j∈S=012…N.
πj=π0d/2πjd+πj+1a/2forj=1,2,..N−1πNa/2forj=NE29
Some specific applications of control chat methods are discussed in [5, 14] (Figure 2).
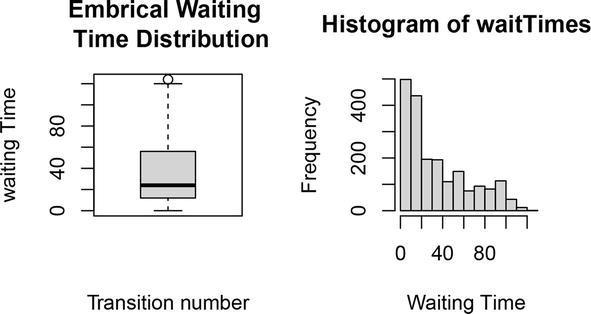
Figure 2.
Box plot and histogram of waiting times.
Detailed information that explores applications of HOMM and data sequence analysis using fuzzy sets are found in [15, 16, 17, 18]. Theory of Fuzzy sets was introduced by Zadeh [19].
3.3 Numerical evaluation of a simulated Ms/Ms/1/N queue
Now, with a simulation study of M = 1000 patients, we try to perform the queuing functions of a health care unit in a way that ensures the best results of an Ms/Ms/1/N queue. The processing time per customer is exponentially distributed with an average rate of μ = 0.27. Patients arrive randomly, with an average of one position every 4 minutes, and are treated on a first come, first served basis. The simulation route is run with an exponential arrival rate λ = 0.25 and an exponential service μ using r-code to implement the algorithm described above.
The rth raw moment of the EQL is given by EYr=Σj=0Njπj.
The estimated values of the all 2000 (= 1000 arrival point and 1000 departure epochs) transition epochs tn: n = 1,2, …, 2000 and the corresponding waiting time Wn = Ln/λ of patients are calculated.
A box-and-whisker diagram of the waiting time distribution Wn: n = 1,2, …, 2000 and its histogram are displayed side by side in Figure 2. As expected, the box-and-whisker plot shows the sizes, spread, and skew of the interquartiles (Q1 = 12, Q2 = 24, Q3 = 56), max = 124, and whiskers (bottom = 0, top = 122) outside the upper and lower quartiles of waiting times. In addition, one exterior remains above the upper whisker, i.e., max Wn: n = 1,2, …, 2000 = 124. Using these facts together with some facts revealed by the histogram, we can conclude that the waiting time distribution can follow, approximately, an exponential distribution with a long tail to the right. A control chart (Figure 3) is designed to show additional information of the pair sequence {(tn, Wn): n = 1,2,…,2000}.
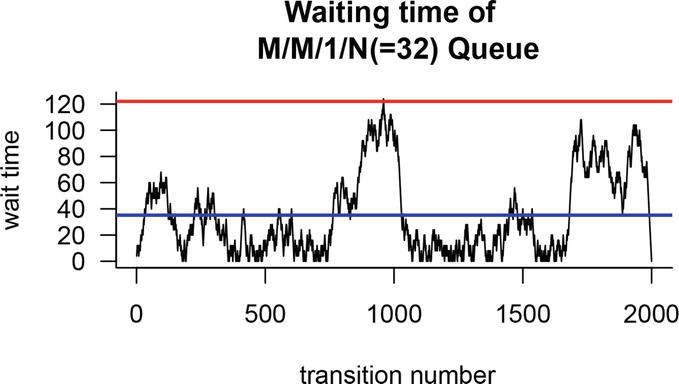
Figure 3.
Transition epochs vs. waiting times.
Any “health” management can refer to the Figure 3 and make certain decisions. First, management must maintain all types of resources necessary to treat and accommodate up to N = 32 patients, such as beds, medical equipment. Second, management can inform patients that the average waiting time is about 35 minutes and the maximum waiting time is about 124 minutes. If the administration installs an additional server during the transition periods of 995 and 1005, the patient’s waiting time can also be reduced. So this section explores how simulation technology can be used to build Markov-type queuing models and use it to better serve ordinary people.
This section discusses different characteristics of an higher-order Markov model (HOMM). The purpose is to explore briefly how a HOMM can be used in forecasting of time series observed over agricultural productions, stock market prices, oil demand, etc. The first step is to covert the given time series into a categorical sequence by fuzzifying the given time series {X(t): t = 0, 1, …,} over a finite number states ∈M=12…m. This type of forming of Markov categorical sequence was developed [20, 21].
The main advantage of using fuzzy logic is that it can handle imprecise data by assigning degrees of truth, called membership values in the closed interval [0,1]. It is an extension of the crisp method to a multivariate format. Since 1965, fuzzy set theory [19] has occupied various fields of our society, see [17, 18, 22]. For fitting a higher order multivariate Markov chain model, basic details can be found in Ref. [23].
We now focus on the data sequence {Xt = j}. Let the initial probability vectors of size “m” in canonical form be denoted by Xt = Pr(Xt = j) = (0, 0, …, 1, 0,…, 0)T} for t = 0,1,…, n. Each m-vector Xt produces a conditional probability distribution of the categorical sequence for a given t. The corresponding normal form of the probability vector be X¯t=1n+1∑t=0nXt.
Hence, each probability vector of size “m” of the sequence X¯t=x1tx2t…xmt produces a conditional probability distribution of the categorical sequence for a given t. If the probability distribution at time t = r + 1 is dependent on the state probability vectors of t = r, r-1, r-2, .., r-n + 1, then the nth order model is formulated as follows:
X¯r+1=∑h=1nλhPhX¯r−h+1E30
The initial probability vectors are X¯t:t=0,1,..,n−1.λh are non-negative real numbers with ∑h=1nλh=1 and each Ph is the h-step transition probability matrix with each column sum equals unity for h = 1, 2, …, n. Numerical evaluation of Ph matrices and the scalars λh for h = 1, 2, …, n can be done with the “markovchain” package. Now, we can make use of the higher-order Markov model fitted by (19) for prediction future states after n-steps. The prediction of the next state X¯t=Pt−1X¯t‐1 at time t can be taken as the state with the maximum probability, i.e.,
X¯t=jifX¯t=k≤X¯t=jk,j=1,2,…mE31
To evaluate the performance and effectiveness of the HOMM, a prediction error (PE) is defined (21):
PE=1K∑j=1Kδjhereδj=1ifx¯t=j≠xt0ifx¯t=j=xtE32
Example: Categorical data sequence and Fuzzy time series We now consider a hypothetical data on amount of rainfall (RF) time series X(t) = {xt} observed from t = 1991 to t = 2001 years which is reported in Table 1. Let the universe of discourse of the ARF factor be U = [100, 1300]. We partition the set U into 4 equal length intervals as follows: u1 = [100, 400), u2 = [400, 700), u3 = [700, 1000), u4 = [1000, 1300] which are mutually disjoint such that U=∪j=14uj.
Year
o(ARF)
o(S1)
E(S1)
E(ARF)
o(S2)
E(ARF)
1991
500.8
A2
NA
NA
NA
NA
1992
254.7
A1
A1
250
NA
NA
1993
982.3
A3
A3
850
A2A3
A2 A2
1994
590.9
A2
A2
550
A1A2
A1 A2
1995
153.4
A1
A1
250
A3A1
A3 A4
1996
875.4
A3
A3
850
A2A3
A2 A4
1997
1250.5
A4
A4
1150
A1A4
A1 A4
1998
1125.7
A4
A4
1150
A3A4
A3 A4
1999
622.6
A2
A2
550
A4A2
A4A2
2000
272
A1
A1
250
A4A1
A4A1
2001
623.4
A2
A3
850
A2A2
A2 A2
Table 1.
HOMM model fitting.
A Rainfall during 1991–2001. ARF = Rainfall amount, S1 = Linguistic Variable for ARF and expected states E(S1) from fitted Markov Model X(t + 1) = P1 Xt and X(t) = P2 X(t − 1).
Let us define fuzzy sets to represent each division uj of U through a linguistic variable, say A, as follows: A1—low if x(t) ∈ u1, A2—medium if x(t) ∈ u2, A3—high if x(t) ∈ u3, A4—very high if x(t) ∈ u4. Thus, there is a one to one correspondence between the rainfall amount x(t) received at time “t” and the values Aj for j = 1,2,3 and 4 of the linguistic variable A.
The observed categorical data sequence for the rainfall amount recorded in Table 1 is coded by S1 = “2,” “1,” “3,” “2,” “1,” “3,” “4,” “4,” “2,” “1,” “2” or by S1 = “A2,” “A1,” “A3,” “A2,” “A1,” “A3,” “A4,” “A4,” “A2,” “A1,” “A2.” This representation given in the sequence S1 forms a fuzzy time series. In addition, the collection of all members of S1 i.e., S=“A1”“A2”“A3”“A4” can be viewed as the finite state space of a Markov Chain (MC) process over a period of time “t” but appropriate order of the MC is not known.
Using the sequence S1, one can fit the first-order MC (FOMC) X¯t+1=λ1PtX¯t for predicting the next state from a given state of the state space S=“A1”“A2”“A3”“A4”.
By combining two adjacent states of the sequence S1 of 11 elements, we can obtain the initial sequence S2 = {A2 A1, A1A3, A3A2, A2A1, A1A3, A3A4, A4A4, A4A2, A2A1, A1A2} of 10 elements for constructing the second-order MC (SOMC). However, in each pair, say AjAk, the second position Ak is representing the current state since the Markov property forgets the past once the current state is known.
Fitting of First- and Second-order Markov models Let us fit FOMC to the observed sequence S1 = “2,” “1,” “3,” “2,” “1,” “3,” “4,” “4,” “2,” “1,” “2” using the “markovchain’ software package applied in R-programming. The command fitHigherOrder(S1,order = 2) is executed and the following results for the parameters of the HOMM given in (19) are obtained:
Consider the fit X¯1=λ1P1X¯0. Because the first column of the matrix P̂1 has the highest probability of 0.67 in the relation of the third row, which is the expected state after one step of state A.1 is A3, that is, A1 → A3. Thus, the expected AMR is calculated as the average of the limits from u3 = [700, 1000), i.e., E(AMR) = (700 + 1000)/2 = 850.
The maximum probability of the second column of the matrix P̂1 occurs in relation to the first row, starting from the observed state A2, to which the MC would reach the state A1 and the expected AMR, which is calculated from u1 = [100 00) is 250. Our conclusion is A2 → A1.
The maximum probability (i.e., 0.5) of the third column of the matrix P̂1 occurs in the second and fourth rows. Thus, starting from the considered state A3, the MC would reach either state A2 or A4 and the expected AMR calculated by u2 = [00700) is 550 and the expected AMR calculated by u4 = [1000,1300) is 1150: P(A3 → A2) = P(A3 → A4) = 0.5.
The maximum probability of the fourth column of the matrix P̂1 is 0.5 relative to rows 2 and 4. Thus, starting from the observed state A4, the MC would reach either state A2 or A4, and the expected AMR calculated by u2 = [400700) is 550 and the expected AMR calculated by u4 = [1000,1300) is 1150: P(A4 → A2) = P(A4 → A4) = 0.5.
When comparing the states specified in columns o(ARF) and E(S1) of the table-(\ref.*{T1}), the prediction error, or PE, is calculated using the formula (\ref) *{ER}): PE = (1/ 10) = 0.1.
Steady state stationary distribution X¯: Since the unit step transition probability matrix of the first order MC is P̂1, the steady state stationary distribution X¯ is the solution of
X¯=P1X¯E34
Executing the command steadyStates(P1) in the “markovchain” package in R code, we obtain that X¯=0.30.30.20.2.
Second-order MC: Steady state stationary distribution X¯2 Consider the initial sequence S2 = {A2 A1, A1A3, A3A2, A2A1, A1A3, A3A4, A4A4, A4A2, A2A1, A1A2} of 10 elements for constructing the SOMC. Each state has a pair of items such as AjAk in which Ak is the current state. We now discuss the analysis of the model fit using the estimates of λ values and the TPMs in the following expression:
X¯2=λ1P1X1+λ2P2X¯0E35
Applying the similar arguments on the factor X¯1=P2X¯0, we can arrive at the following conclusions: C1: A1 → A2 or A1 → A4.
A2→A3
A3→A1orA3→A4
A4→A1orA2→A2
Repeating the similar exercise on the factor X¯2=P1X¯1, we can arrive at the following conclusions:
C2
A1→A3
A2→A1
A3→A2orA3→A4
A4→A2orA4→A4
Now, ordering the results of C1 with C2 in this order we obtain the expected second-order sequences at the end of the second state: A1 A1 or A1 A2 or A1 A4.
Prediction error for SOMC fit is PE = (3/9) = 0.33.
It can be shown that the matrix P = λ1P1 + λ2P2 serves as the TPM of the SOMC. Hence, the steady state stationary distribution X¯2 can be obtained by solving the equation X¯2P=X¯2.X¯2=0.26736320.32033550.19462530.2176760.
The prediction error of the FOMC is smaller than that of second-order MC. In addition, there is no significant improvement in the four component stationary probability vector X¯2 as compared to the respective components of first-order vector X¯. So we can conclude that the fFOMC is preferable over the SOMC for future predictions.
This chapter looked at three types of Markov models. The first model addressed the basic issues of a warehouse connected to an M/M/1/N/FCFS facility. The long-run probability distributions of queue length and inventory variables were obtained using matrix methods. The expected total cost function was formulated based on holding costs, ordering costs, and waiting time cost and was used to obtain the optimal order quantity. A graphical representation of the relationship between the cost function and order quantity was provided to support the theoretical results of this model.
The second model investigated the changes made by the arrival and departure phases of the M/M/1/N/FCFS queue and thus analyzed the simulated queue Ms/Ms/1/N for long-term evaluation of moments. The input queue length and waiting times for all consecutive transitions in the Ms/Ms/1/N system were calculated and all were plotted on a control chart to observe the effect of the customer waiting time distribution.
The third model analyzed the HOMM to predict the fuzzy time series as a data series. Two special cases, the FOMC and the SOMC, were fitted to the same dataset generated by measuring the hypothetical rainfall ensemble. Forecast errors for both FOMC and SOMC were calculated and compared to show that the FOMC performed best.
The best conclusions are thus made by analyzing MC models for both waiting line and inventory problems. We developed either numerically tractable expressions or accurate probabilistic expressions to obtain numerical representations. The first model can be recommended for any QIM problem and the second model to quickly assess waiting times in medical resources to ensure the best quality of service. A third model can be conveniently used to predict future states of categorical datasets with higher orders.
Future research will develop intelligent and easy-to-implement algorithms for the interdisciplinary researchers.
The author would like to thank two colleagues for their comments on Markov models, which greatly helped this chapter of the book.
References
1.Gross D, Harris SM. Fundamentals of Queueing Theory. 3rd ed. New York, NY: Wiley; 1998
2.Bhat N. An Introduction to Queueing Theory: Modeling and Analysis in Applications. 2nd ed. Boston: Birkhauser; 2008. p. 268. DOI: 10.1007/978-0-8176-4725-4
3.Spedicato GA. Discrete Time Markov Chains with R. The R Journal. 2017. Available from: https://journal.r-project.org/archive/2017/RJ-2017-036/index.html
4.Hunter JJ. Filtering of Markov renewal queues, II: Birth-death queues. Advanced in Application Problem. 1983;15:376-391
5.Sivasamy R, Jayanthi S. Charts for detecting small shifts. Economic Quality Control. 2003;8(1):1-8
6.Sivasamy R, Thillaigovindan N, Paulraj G, Paranjothi N. Quasi-birth and death processes of two server queues with stalling. OPSEARCH. 2019;56:739-756. DOI: 10.1007/s12597-019-00376-1
7.Sivasamy R. An M/M(1)+M(2)/1 queue with a state dependent K-policy. Journal of Xi’an University of Architecture & Technology. 2021;I:111-124
8.Taylor HM, Karlin S. An Introduction to Stochastic Modeling. 3rd edition. San Deigo, CA: Academic Press; 1998. ISBN-10: 0126848874, ISBN-13: 978-0126848878
9.Zhang Y, Yue D, Sun L, Zuo J. Analysis of the queueing-inventory systems with impatient customers and mixed sales. Discrete Dynamics in Nature and Soceity. 2022;2022:1-12. DOI: 10.1155/2022/2333965
10.Alnowibet KA, Alrasheedi AF, Alqahtani FS. Queueing models for analysing the steady-state distribution of stochastic inventory systems with random Lead time and impatient customers. Process. 2022;10:1-24. DOI: 10.3990//pr10040624
11.Daduna H, Szekli R. M/M/1 queueing systems with inventory. Queueing System. 2006;54:55-78. DOI: 10.1007/s11134-006-8710-5
12.Schwarz M, Daduna H. Queueing systems with inventory management with random lead times and with backordering. Mathematical Methods of Operational Research. 2006;64:383-414
13.Latouche G, Ramaswami V. Introduction to Matrix Analytic Methods in Stochastic Modeling: ASA-SIAM Series on Statistics and Applied Probability. Philadelphia, PA: SIAM; 1999
14.Shore H. General control charts for attributes. IIE Transactions. 2000;32(12):1149-1160
15.Berman O, Kim E. Stochastic models for inventory management at service facilities. Communication Statistical Stochastic Model. 1999;15(4):695-718
16.Berman O, Kim E. Dynamic order replenishment policy in internet-based supply chains. Mathematical Method Operations Research. 2001;2001:53
17.Song Q, Chissom BS. Forecasting enrollments with fuzzy time series – Part I. Fuzzy Sets and Systems. 1993;54:1-9
18.Wong W-K, Bai E, Chu AW. Adaptive time-variant models for fuzzy-time-series forecasting. IEEE Transaction System on Man Cybernetics: Part B. 2010;40:1531-1542
19.Zadeh LA. Fuzzy sets. Information and Control. 1965;8(3):338-353. DOI: 10.1016/S0019-9958(65)90241-X
20.Ching WK, Fung ES, Ng MK. Higher-Order Markov Chain models for categorical data sequences. Naval Research Logistics. 2004;2004:557-574. DOI: 10.1002/nav.20017
21.Ching WK, Ng MK, Fung ES. Higher-order multivariate Markov chains and their applications. Linear Algebra and Its Applications. 2008;428:492-506
22.Singh P, Borah B. Forecasting stock index price based on M-factors fuzzy time series and particle swarm optimization. International Journal of Approximate Reasoning. 2014;55:812-833. DOI: 10.1016/j.ijar.2013.09.014
23.Sivasamy R, Senthamaraikannan K, Adebayo Fatai A, Karuppasamy KM. Higher order Markov chain fitting for data on rainfall and Rice production. YMER. 2021;20(10):156-170
Written By
Sivasamy Ramasamy and Wilford B. Molefe
Submitted: 18 December 2022Reviewed: 09 March 2023Published: 26 April 2023
 Open access peer-reviewed chapter
Open access peer-reviewed chapter