Open Access is an initiative that aims to make scientific research freely available to all. To date our community has made over 100 million downloads. It’s based on principles of collaboration, unobstructed discovery, and, most importantly, scientific progression. As PhD students, we found it difficult to access the research we needed, so we decided to create a new Open Access publisher that levels the playing field for scientists across the world. How? By making research easy to access, and puts the academic needs of the researchers before the business interests of publishers.
We are a community of more than 103,000 authors and editors from 3,291 institutions spanning 160 countries, including Nobel Prize winners and some of the world’s most-cited researchers. Publishing on IntechOpen allows authors to earn citations and find new collaborators, meaning more people see your work not only from your own field of study, but from other related fields too.
To purchase hard copies of this book, please contact the representative in India:
CBS Publishers & Distributors Pvt. Ltd.
www.cbspd.com
|
customercare@cbspd.com
Performance measurement is essential for fostering continuous improvement of the production and operation management in a firm or organization. We consider a deterministic scenario based on a flexible structure of production technology and establish a multiplicative relationship between the generalized multiplicative directional distance function (GMDDF) and geometric distance function (GDF). We also introduce a stochastic multiplicative directional distance function (SMDDF). Based on a stochastic scenario, the SMDDF can be estimated by the method of convex nonparametric least squares. As an illustrative application, we investigate the productive performance of Japanese life insurance companies using a panel dataset spanning 2016 to 2020.
Keywords
performance measurement
stochastic multiplicative directional distance function
*Address all correspondence to: yu.zhao@rs.tus.ac.jp
1. Introduction
The purpose of this study is to establish the relationship between the generalized multiplicative directional distance function (GMDDF, [1]) and the geometric distance function (GDF, [2]), and to develop a stochastic multiplicative directional distance function (SMDDF) for performance measurement. The GMDDF and GDF are commonly measured by data envelopment analysis (DEA, [3]), a deterministic nonparametric method applicable to multiple-input and multiple-output production technologies. Although the GMDDF and GDF have a multiplicative nature, the original GDF is measured based on a convex production possibility set, whereas the GMDDF is developed with a non-convex production possibility set. From a practical perspective, the convexity assumption may be strong if significant degrees of increasing returns exist. To address a flexible structure of production technology, previous studies in DEA also studied a non-convex production possibility set based on a geometric convexity assumption [1, 4]. The methodology of this study is based on a geometric convex production possibility set, which implicitly models a piecewise log-linear technology. Moreover, it is well known that a one-to-one correspondence relationship exists between the piecewise log-linear technology and the conventional piecewise linear technology. This makes it possible to apply the conventional DEA methods to approach the multiplicative models developed for a geometric convex production possibility set. Therefore, measuring the multiplicative type distance functions is of practical and theoretical interest.
It is also well known that DEA commonly discounts stochastic noise, suggesting that any deviations from the frontier (e.g., gauging the distance to the boundary of the production technology) can be considered a measure of pure inefficiency. By contrast, stochastic frontier analysis (SFA, [5]), a general stochastic parametric approach, accounts for stochastic noise by treating all deviations from the frontier as aggregations of both inefficiency and noise. However, compared with the flexibility of nonparametric measurements, because SFA is a parametric methodology, it relies heavily on an accurately prespecified functional form for production technology. Recently, stochastic nonparametric envelopment of data (StoNED) has been introduced in the literature on efficiency analysis. The StoNED approach relies on the method of convex nonparametric least squares (CNLS), which is a nonparametric regression technique [6]. Both SFA and StoNED are based on a convex production possibility set. This study introduces a stochastic multiplicative directional distance function (SMDDF) based on the geometric convex production possibility set and further proposes an estimation model using CNLS.
The methodology of this study consists of two basic scenarios: deterministic and stochastic. These are performed simultaneously to analyze the productive performance of Japanese life insurance companies. The application demonstrates the advantage of using a combination of GMDDF/GDF and SMDDF, enabling comprehensive understanding of the Japanese life insurance industry.
Consider a sample of n decision-making unitis (DMUs). Denote xj=x1j…xmjT∈R++m and yj=y1j…ysjT∈R++s as positive input and output vectors of DMUj (j=1,…,n), respectively. The superscript T stands for a vector transpose. A production technology that transforms inputs into outputs can be defined by the following production possibility set:
P≔xy∈R++m×R++sxcanproducey,
where P contains the input and output vectors xjyj for all j=1,…,n. The conventional DEA-based production technology assumes that P is a closed, bounded, and convex set that satisfies free disposability (see, e.g., [7, 8]). In particular, the ordinary convexity assumption, which is described as below,
requires the marginal products to be nonincreasing. However, this cannot be used to understand productive performances characterized by significant degrees of increasing returns so that the marginal products of inputs may be low with a small-scale economy and may increase sharply as the scale expands beyond a threshold (see, e.g., [9]). To allow a flexible structure of production technology, previous studies [1, 4] postulated a geometric convexity assumption, as below:
where ⊗ stands for the element-wise multiplication of vectors. By replacing A1 with A1′, P is not restricted to be concave (e.g., the underlying production function can be S-shaped) and is capable of capturing the potential existence of increasing, constant, or decreasing marginal products. For empirical studies that use a non-concave production technology, see [10, 11], among others.
In this study, we proceed with the performance measurement using P that satisfies closedness, boundedness, geometric convexity, and free disposability. Based on a given P, the generalized multiplicative directional distance function (GMDDF, [1]) is defined as
where g≔−g−g+∈−R+m×R+s is a prespecified direction vector and
α−g−≔α1−g1−⋯0⋮⋱⋮0⋯αm−gm−andβg+≔β1g1+⋯0⋮⋱⋮0⋯βsgs+.
According to definition (1), both inputs and outputs are changed simultaneously along with a given direction g and are eventually projected onto the frontier (boundary) of P. Denote the points on the frontier of P as x∗y∗. We hereby list the main properties of Mxy−g−g+ used in this study, as below (See [1] for details on the proofs):
P1: Mxy−g−g+≥1 if and only if xy∈P.
P2: Mx∗y∗−g−g+=1 for any given −g−g+∈−R+m×R+s.
P3: logMxy−g−g+ is concave on logP,
where logP≔logxlogy∈Rm×Rs(xy)∈P.
The property P1 means that Mxy−g−g+ is a functional representation of P, that is
We first consider a deterministic scenario, in which all producible input-output vectors are only affected by inefficiencies.
Proposition 1.1. Let δxi≤1 for all i=1,…,m and δyr≥1 for all r=1,…,s. Assume that a projection point x∗y∗ for the DMU xy is achieved by improving xy at exponential changes of a vector δx1δy by the power of a given vector g−−g+∈R+m×−R+s. Specifically,
It is worthnoting that Eq. (4) is equal to the reciprocal of the geometric distance function (GDF) introduced by [2]:
ϕ≔∏i=1mδxi1m∏r=1s1δyr1s,
which is a non-oriented efficiency measure that incorporates both input contraction and output expansion toward the projection points. Note that the original GDF is developed based on the ordinary convexity assumption. However, it is possible to reformulate the GDF on a given P (that satisfies geometric convexity). In such a case, the GDF can be considered a specific case of the GMDDF with −g−g+=−1m1s, that is, Mxy−1m1s. In the scenario described in Proposition 1, the relationship between the GMDDF and GDF can be stated as
Mx∗y∗−g−g+=Mxy−1m1s×Mxy−g−g+=ϕ×Mxy−g−g+.
Consequently, u=1/ϕ can be used as an inefficiency measure with a range of 1∞.
3. A stochastic multiplicative directional distance function
In this section, we further consider a stochastic scenario in which all observations (i.e., xjyj,∀j=1,…,n) in P are random variables and have their unique deterministic projection point (efficient point) on the frontier of P (i.e., xj∗yj∗,∀j=1,…,n). We assume that the difference between the observation point and the projection point is not only caused by the inefficiency term but also by random noise. Since the generalized multiplicative directional distance function ranges from 1 to ∞, it does not have a straightforward representation to describe the stochastic setting. Therefore, we introduce a stochatsic multiplicative directional distance function (SMDDF), which is defined as follows:
Some properties of M˜xy−g−g+ are described as below:
P1’: M˜xy−g−g+>0 if and only if xy∈P.
P2’: M˜x∗y∗−g−g+=1 for any given −g−g+∈−R+m×R+s.
P3’: logM˜xy−g−g+ is concave on logP,
where logP≔logxlogy∈Rm×Rs(xy)∈P.
The property P1’ is evident from the definition (5). P2’ holds because the frontier containing all of the projection points x∗y∗ is assumed to be deterministic. P3’ can be proved in a similar way with P3 (see [1] for further details). Furthermore, M˜xy−g−g+ has the following translation property:
Proposition 1.2. For any positive vector θη∈R++m+s,
It is worth noting that the proposed M˜xy−g−g+ precisely reveals a multiplicative data-generating process. To help inform intuition regarding this type of data-generating process, let ϵxi>0 for all i=1,…,m and ϵyr>0 for all r=1,…,s be the element-specific composite errors for inputs and outputs, respectively. Since x and y are random variables that are subject to both inefficiencies and noises, we assume that Eϵxi=μxi>0, Varϵxi<∞ and Eϵyi=μyi>0, Varϵyi<∞. Suppose that
xy=ϵxg−x∗ϵy−g+y∗.E6
Then, it follows from Proposition 1.2 and property P2’ that
logM˜xy−g−g+=1m∑i=1mlogϵxi+1s∑r=1slogϵyr,E7
which is equivalent to
M˜xy−g−g+=∏i=1mϵxi1m×∏r=1sϵyr1r.
To simplify the notation, we define ϵ≔∏i=1mϵxi1m×∏r=1sϵyr1r. Then,
M˜xy−g−g+=ϵ.
Therefore, M˜xy−g−g+ can be interpreted as a composite error term that is constructed with ϵxi∀i and ϵyr∀r. Moreover, from the linearity of expectation and Jensen’s inequality, we also have 0<μ≔Elogϵ=E1m∑i=1mlogϵxi+1s∑r=1slogϵyr≤1m∑i=1mlogμxi+1s∑r=1slogμyr.
To estimate the inefficiency for the observed DMUj (j=1,…,n) as well as the SMDDF, we apply Proposition 1.2 and set θjηj=xjyj to obtain the following equality:
It follows from P3 that M˜x˜jy˜j−g−g+ is a concave function. Moreover, M¯¯x˜jy˜j−g−g+ could be seen as the conditional expectation function of 1m∑i=1mlogxij+1s∑r=1slogyrj. That is,
1m∑i=1mlogxij+1s∑r=1slogyrj=M¯¯x˜jy˜j−g−g+−ξj,
where ξj=loguj+vj−μ and uj is a DMU-specific inefficiency term that satisfies Eloguj=μ, Varloguj<∞, and vj is a noise term that satisfies Evj=0, Varvj<∞.
To estimate M¯¯x˜jy˜j−g−g+ as well as the average level of inefficiencies, we apply the method of convex nonparametric least squares (CNLS, [6]), which is a nonparametric regression approach with a least-square objective subject to monotonicity and convexity/concavity constraints. However, the definition of SMDDF requires additional conditions that Proposition 1.2 should hold, contrary to constraints of the ordinary CNLS problem. Therefore, we formulate the CNLS problem as the following quadratic programming (QP) problem:
The objective function (8) and the constraint (9) fit a linear equation for each DMUj, where 1m∑i=1mlogxij+1s∑r=1slogyrj is the dependent variable and x˜j−y˜j is the independent variable. The second constraint (10) further imposes Afrait’s theorem [12], which ensures global concavity of the estimated M¯¯x˜jy˜j−g−g+. The third constraint (11) ensures the translation property as described in Proposition 1.2. The last two constraints in (12) impose monotonicity relative to all transformed inputs x˜j and outputs y˜j. Using the translation property, the above problem can be reformulated as
where the constraint (14) now is a linear equation of inputs and outputs for each DMUj. Since the problems (13)–(17) estimate M¯¯x˜jy˜j−g−g+ as a concave function, the coefficients υj,ζij,γrj,∀i,r characterize a tangent hyperplane of the estimated M¯¯x˜jy˜j−g−g+ for each DMUj.
After solving the problem (13)–(17), it is possible to derive the expected value of the logarithm of inefficiencies (i.e., μ) based on the skewness of the estimated residuals. For example, μ can be measured using the method of moments [5] (Note that alternative approaches such as quasi-likelihood estimation and nonparametric kernel deconvolution are available. See, e.g., [13] for a detailed discussion).
4. Application to Japanese life insurance companies
In this section, we investigate the productive performance of Japanese life insurance companies by considering both deterministic and stochastic scenarios. The sample consisted of 41 member companies of the Life Insurance Association of Japan (LIAJ). We considered the sample years 2011–2020. The data were drawn from the financial statements of all companies or the Summary of Life Insurance Business 2021 as published by LIAJ.
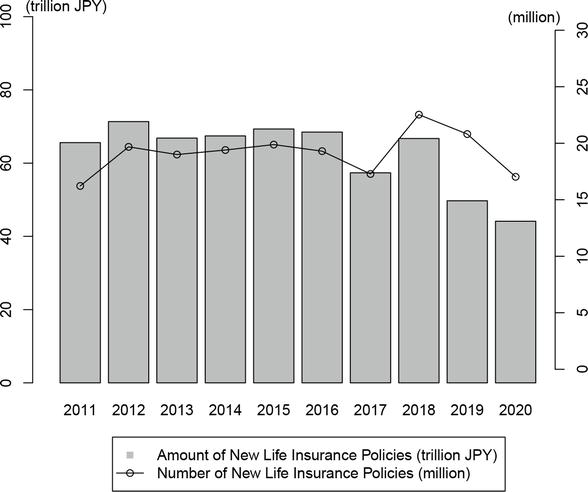
Life insurance companies play an essential role in the financial and loan markets in Japan [14]. Many of them have relied predominantly on face-to-face sales for a long period. However, since the beginning of the COVID-19 pandemic, Japanese life insurance companies were forced to temporarily suspend their face-to-face sales channels due to the nationwide declaration of a state of emergency. As shown in Figure 1, domestic sales of new policies have declined significantly since (fiscal year) 2018. According to the Life Insurance Factbook 2019 published by LIAJ, the decrease in 2019 was primarily due to lower sales of foreign currency-denominated insurance. In 2020, the conditions of domestic sales in new policies became even worse because insurance agents could not meet new customers directly. According to the monthly statistics of LIAJ, the number of new businesses reduced by 34.4% in April and 68.5% in May, on a year-on-year basis during the period of the first declaration of a state of emergency from 2020/4/7 to 2020/5/25. Moreover, even though Japanese life insurance companies resumed face-to-face sales after the state of emergency was lifted, the year-on-year decline in 2020 continued until August (14.3%).
Figure 1.
Trends in individual life insurance business (source: Life Insurance Association of Japan (LIAJ)).
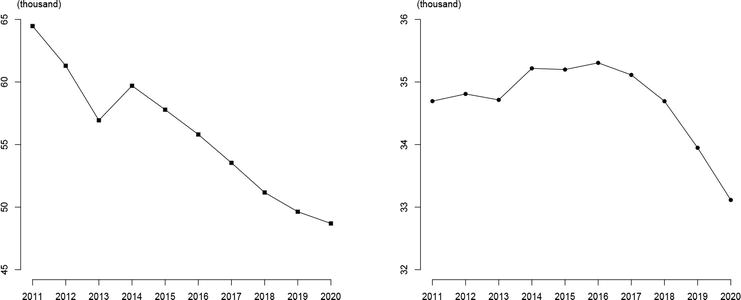
Japanese life insurance companies have changed their distribution channels over the past 10 years. It can be seen from Figure 2 that the numbers of individual and corporate agencies have been decreasing gradually in recent years. This trend should not be taken as proof that the scale of the life insurance industry has shrunk. In fact, Japanese life insurance companies have become more diversified in their sales channels due to diversifying insurance products and consumer needs and a recently increasing presence of non-traditional sales channels, such as Internet sales. Considering that life insurance companies must refrain from face-to-face sales to prevent the spread of COVID-19, a significant diversion of sales channels may lead to better performance, such as shifting from the traditional business model of face-to-face sales to online sales channels. However, sales representatives in agencies remained the primary sales channel of life insurance in 2020 [15].
Figure 2.
Distribution channels (source: Life Insurance Association of Japan (LIAJ)).
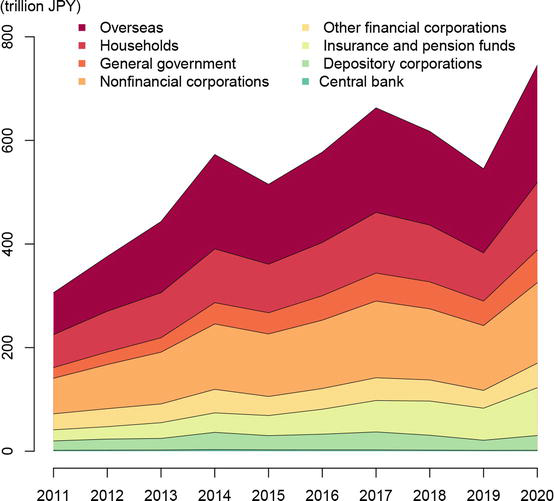
Japanese life insurance companies also play a critical role as stable institutional investors in the capital market as they hold a certain level of listed shares for a long period. Figure 3 shows the breakdown of listed shares by type of shareholder. It can be seen that the amount of listed shares held by insurance companies (insurance and pension funds) has been increasing over the past 10 years. Thus, measuring the behavior of insurance companies makes economic sense. In addition, it has been widely recognized that the current solvency margin ratio regulation introduced in 1996 does not adequately assess the valuation of liabilities and the amount of risk. This issue is expected to be solved by introducing economic value-based solvency regulations. According to the report on the economic value-based solvency framework released by the Financial Services Agency (FSA) of Japan in June 2020, the economic value-based solvency regulation will be enforced from April 2025. Since new regulations may change the business environment of Japanese life insurance companies and affect their behavior, it makes practical sense to study the past and present productive performance of Japanese life insurance companies to better prepare for the arrival of new regulations.
Figure 3.
Breakdown of listed shares by type of shareholder (source: Bank of Japan).
4.1 Inputs and outputs
To characterize the inputs and outputs of Japanese life insurance companies, we applied a value-added approach that has been commonly used in previous studies (see, e.g., [16] for a detailed discussion of the value-added approach). We considered three inputs and two outputs. The inputs were “office workers (x1),” “total shareholders’ equity (x2),” and “operating expenses (x3).” The first two variables, office workers and total shareholders’ equity, were proxy variables for labor and capital, respectively. The operating expenses included various cost items required to operate the life insurance business, such as the selling cost, management/maintenance-related cost, and others. In contrast, the outputs were “ordinary income (y1)” and “total payment of insurance benefits (y2).” Ordinary predominately derives from the insurance business, such as premium income and investment-related business, the latter of which includes interest and dividend income. To account for the risk-pooling and risk-bearing capabilities of Japanese life insurance companies, we also considered the total payment of insurance benefits as a proxy output variable.
The descriptive statistics of inputs and outputs are summarized in Table 1.
Units of x2, x3, y1, y2: trillion yen; the unit of x1: person.
4.2 Deterministic scenarios
In previous studies, the geometric distance function (GDF) was measured a posteriori after the projection points were computed due to its nonlinearity [2, 17]. In Section 2, we showed that for a certain deterministic scenario (see, Proposition 1.1), the value of generalized multiplicative directional distance function Mxy−g−g+ is equal to the reciprocal of GDF. In this section, we calculated the GDP for each Japanese insurance company using the function Mxy−g−g+.
For any 1δxδy≥1m1s, the function Mxy−g−g+ can be measured by the following nonlinear programming (NLP) problem:
Let δxi∗δyr∗λj∗,∀i,r,j be an optimal solution to the above model. Then, the GDF can be computed by
ϕ∗=∏i=1mδxi∗1m∏r=1s1δyr∗1s.
From a theoretical perspective, an exogenously given direction vector g−g+ is preferred for the determination of projection points. However, from a computational perspective, the direction vector in the above model can be chosen arbitrarily. In practice, the decision-makers may choose proper direction vectors depending on their purpose of performance benchmarking, or alternatively, use the direction vectors that lead to unit-invariant efficiency measures (See, e.g., [1] for detailed discussion on selecting direction vectors). In this study, we adopted gi−gr+=logxio−minj∈1…nlogxijmaxj∈1…jlogyrj−logyro,∀i,r to derive the unit-invariant GDF efficiencies.
The estimated GDF efficiencies are reported in Table 2. There were three efficient companies over the fiscal years 2016–2020: DMU05 (AEON Allianz Life Insurance Co., Ltd.), DMU18 (The Dai-ichi Frontier Life Insurance Co., Ltd.), and DMU41 (Rakuten Life Insurance Co., Ltd.). These companies can be seen as adopting best practices that were sustainable given the challenges of a changing business environment over the whole period. In addition, we also found that the Japanese life insurance industry is experiencing a downturn in performance, as the average efficiency score declined from 2016 to 2020.
The number of DMUs follows the order of the member companies of the Life Insurance Association of Japan (LIAJ), as released on November 2, 2021. We excluded HANASAKU LIFE INSURANCE Co., Ltd. from the sample because it is a new member as of April 1, 2019.
The average values of δx∗1δy∗ are summarized in Table 3. The parameters δx∗ and 1δy∗ can be interpreted as the element-specific efficiencies for inputs and outputs, respectively. It can be seen from Table 3 that the input “total shareholders’ equity (x2)” had the highest average efficiency score versus the other inputs and outputs over the period 2016–2020 (the mean of δx2∗ was 0.861). The second highest average efficiency score was achieved by “operating expenses (x3)” (the mean of δx3∗ was 0.808). This indicates that Japanese life insurance companies have good performance in funding-related inputs. By contrast, the input “office workers (x1)” had the lowest average efficiency score (the mean of δx1∗ was 0.67), which implies that Japanese life insurance companies have relatively poor performance in human resources. This may be due to the paradigm shift in the face of an increasing number of new sales channels. Additionally, since Japanese life insurance companies could not meet new customers directly in order to prevent the spread of COVID-19 in 2020, the decreased efficiency score in 2020 compared to 2019 may due to the impact of the nationwide declaration of a state of emergency. However, further investigations are needed regarding this issue.
Year
δx1∗
δx2∗
δx3∗
1δy1∗
1δy2∗
2020
0.667
0.925
0.751
0.661
0.73
2019
0.704
0.867
0.85
0.65
0.699
2018
0.648
0.85
0.803
0.794
0.77
2017
0.651
0.833
0.815
0.782
0.78
2016
0.681
0.828
0.819
0.798
0.821
mean
0.67
0.861
0.808
0.737
0.76
Table 3.
Results of the estimated δx∗1δy∗.
4.3 Stochastic scenarios
Compared with the generalized multiplicative directional distance function Mxy−g−g+, the proposed stochastic multiplicative directional distance function (SMDDF) M˜xy−g−g+ is capable of capturing the statistical variation present in the observed data. To facilitate comparison, we applied the same direction vector used in Section 4.2 to estimate the SMDDF. The estimated coefficients characterizing the tangent hyperplanes of the concave SMDDF for all DMUs are summarized in Table 4.
Descriptive statistics of the estimated coefficients.
† represents the DMU with extremely large or extremely small coefficients.
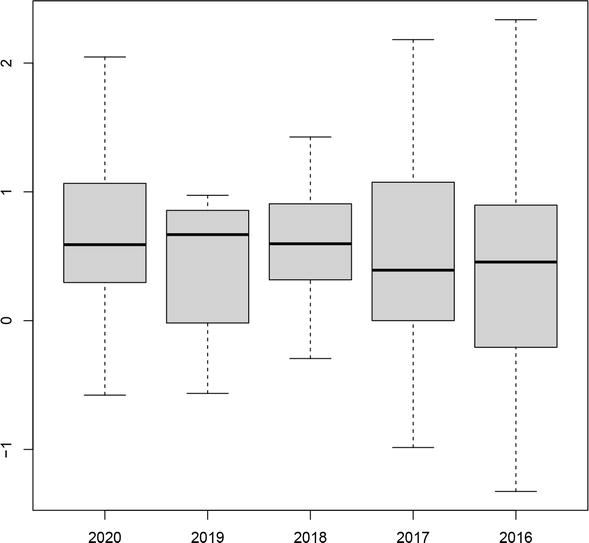
From Table 4, it is clear that the estimated coefficients exhibited significant variance over the period 2016–2020. However, few DMUs had extremely large or extremely small coefficients, and the estimated coefficients of most of the observed DMUs were in the range 0 to 1. This can be intuitively understood, for example, from the box plot of the intercepts υ∗ excluding the extreme values, as shown in Figure 4. We also report the DMUs with extreme values of estimated coefficients for each year in Table 4. Since the coefficients characterize the tangent hyperplane of the concave SMDDF of each DMU, DMUs with extreme values of the estimated coefficients may affect the shape of the estimated concave SMDDF and be identified as efficient DMUs. Indeed, all DMUs with extreme estimated coefficients are also evaluated as efficient DMUs in the deterministic scenario, as shown in Table 2. Moreover, we found that DMU02 is efficient in the deterministic scenario for the period 2018–2020. This observation is consistent with the results of the stochastic scenario. From Table 4, the period when DMU02 had extreme values of the estimated coefficients was also 2018–2020. However, the same is not true for DMU11. DMU11 was efficient in the deterministic scenario in 2016, 2017, and 2020, whereas its estimated coefficients were extreme only in 2020. However, this does not mean that DMU11 is not efficient, because technically, we cannot exclude the possibility that DMUs without extreme estimated coefficients cannot affect the shape of the estimated concave SMDDF. Regarding the efficient DMUs without extreme estimated coefficients in Table 2, they may be overestimated because the deterministic model ignored the impact of random errors.
Figure 4.
Box plot of the intercepts υ∗.
The results of the deterministic scenario show that the Japanese life insurance industry exhibited worse performance between 2016 and 2020. By contrast, the results of the stochastic scenario in Table 5 show that the estimated average inefficiency μ∗ increased from 2016 to 2019 and then decreased, which implies that the Japanese life insurance industry likely performed better in 2020 than in 2019. Since the efficiency scores in 2020 exhibited slightly more variation than those in 2019, as shown in Table 2, the difference in the average performance between the deterministic and stochastic scenarios may be due to the impact of random error. Nevertheless, considering that both approaches have a small range of variation in the average (in)efficiencies (i.e., the deterministic scenario: 0.004,0.08; the stochastic scenario: 0.009,0.056), we conclude that the Japanese insurance industry exhibited relatively stable performance during 2016–2020.
2020
2019
2018
2017
2016
μ∗
0.144
0.166
0.15
0.119
0.11
Table 5.
Results of the estimated expected value of the logarithm of inefficiencies μ∗.
This study considers a flexible structure of production technology that is constructed based on geometric convexity assumption. We investigated the relationship between the generalized multiplicative directional distance function (GMDDF) and geometric distance function (GDF) based on a given geometric convex production possibility set. We show that, given a deterministic scenario, the multiplication of GMDDF and GDF for the observed DMUs has the same value as the GMDDF calculated for the projection points. Based on this relationship, the GDF efficiencies can be easily measured by a DEA methodology. We also proposed a stochastic multiplicative directional distance function (SMDDF) in which all inputs and outputs are considered random variables. Given a stochastic scenario, we show that the SMDDF can be formulated as a CNLS problem. The productive performance of Japanese life insurance companies was investigated. Several companies were identified as efficient DMUs from both the results of the deterministic and stochastic scenarios. These companies can be used as projections for improving inefficiencies. Moreover, it seems that Japanese life insurance companies have a good performance in funding-related inputs since “total shareholders’ equity” and “operating expenses” were more efficient than were other inputs and outputs. By contrast, many of the Japanese life insurance companies may have suffered from poor performance in human resources. Furthermore, both the deterministic and stochastic scenarios suggest a decline in the average performance of the whole life insurance industry during 2016-2019. However, since the variations of average (in)efficiencies over the years are small, it is reasonable to conclude that the Japanese life insurance industry achieved relatively stable performance in the previous five years.
generalized multiplicative directional distance function
LIAJ
Life Insurance Association of Japan
NLP
nonlinear programming
QP
quadratic programming
SMDDF
stochastic multiplicative directional distance function
StoNED
stochastic nonparametric envelopment of data
References
1.Mehdiloozad M, Sahoo BK, Roshdi I. A generalized multiplicative directional distance function for efficiency measurement in DEA. European Journal of Operational Research. 2014;232(3):679-688
2.Portela MCAS, Thanassoulis E. Profitability of a sample of Portuguese bank branches and its decomposition into technical and allocative components. European Journal of Operational Research. 2005;162(3):850-866
3.Charnes A, Cooper WW, Rhodes E. Measuring the efficiency of decision making units. European Journal of Operational Research. 1978;2(6):429-444
4.Banker RD, Maindiratta A. Piecewise loglinear estimation of efficient production surfaces. Management Science. 1986;32(1):126-135
5.Aigner D, Lovell CK, Schmidt P. Formulation and estimation of stochastic frontier production function models. Journal of Econometrics. 1977;6(1):21-37
6.Kuosmanen T. Representation theorem for convex nonparametric least squares. The Econometrics Journal. 2008;11(2):308-325
7.Banker RD, Charnes A, Cooper WW. Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science. 1984;30(9):1078-1092
8.Färe R, Grosskopf S, Lovell CK. The Measurement of efficiency of production. Vol. 6. Dordrecht: Springer Science & Business Media; 1985
9.Majumdar M, Roy S. Non-convexity, discounting and infinite horizon optimization. Journal of Nonlinear and Convex Analysis. 2009;10:1-18
10.Valadkhani A, Roshdi I, Smyth R. A multiplicative environmental DEA approach to measure efficiency changes in the world’s major polluters. Energy Economics. 2016;54:363-375
11.Roshdi I, Hasannasab M, Margaritis D, Rouse P. Generalised weak disposability and efficiency measurement in environmental technologies. European Journal of Operational Research. 2018;266(3):1000-1012
12.Afriat SN. Efficiency estimation of production functions. International Economic Review. 1972;13(3):568-598
13.Kuosmanen T, Johnson A. Modeling joint production of multiple outputs in StoNED: Directional distance function approach. European Journal of Operational Research. 2017;262(2):792-801
14.Fukuyama H. Investigating productive efficiency and productivity changes of Japanese life insurance companies. Pacific-Basin Finance Journal. 1997;5(4):481-509
15.Nobuyasu U. Japan’s insurance market 2021. Tokyo: The Toa Reinsurance Company, Limited; 2021
16.Eling M, Luhnen M. Frontier efficiency methodologies to measure performance in the insurance industry: Overview, systematization, and recent developments. The Geneva Papers on Risk and Insurance-Issues and Practice. 2010;35(2):217-265
17.Portela MCAS, Thanassoulis E. Malmquist indexes using a geometric distance function (GDF). Application to a sample of Portuguese bank branches. Journal of Productivity Analysis. 2006;25(1):25-41
Written By
Yu Zhao
Submitted: 02 March 2022Reviewed: 03 March 2022Published: 24 June 2022
 Open access peer-reviewed chapter
Open access peer-reviewed chapter