
Abstract
Artificial Intelligence [AI] has been of great discussion lately and one can perceive its use in many aspects of modern life. In science, and more specifically in Materials Sciences, AI has been employed for many different applications. Machine Learning (ML) has been historically linked to Artificial Intelligence (AI) for many decades. Some basic concepts of ML can be traced from the 1930s, but it was only during the 1980s and 1990s that ML really started to be used in a stronger and well-organized fashion, due to the development of more efficient algorithms from better and more robust data processing machines. This chapter presents a review on the recent works of distinct research groups that have been using Machine Learning [ML], which is one of many different methods of AI, as a tool for predicting steel properties. A brief definition of ML is given at the beginning of the chapter, followed by some of the most relevant examples of ML use to exemplify the power of this AI method for the development of steel engineering.
Keywords
- steels
- machine learning
- artificial intelligence
- steel properties
- steel engineering
1. Introduction
Machine Learning (ML) has been historically linked to Artificial Intelligence (AI) for many decades. Some basic concepts of ML can be traced from the 1930s, but it was only during the 1980s and 1990s that ML really started to be used in a stronger and well-organized fashion, due to the development of more efficient algorithms from better and more robust data processing machines. In 1995, Cortes and Vapnik [1], from Bell Laboratories, introduced the concept of ML in their work and from that point on, the development of ML has been enormous.
Another significant contribution was the development of
The advent of Machine Learning [ML] [2] has ushered in a transformative era in the industrial landscape, redefining the approach to complex technological challenges and to process optimization. With its foundation in advanced data analytics and computational algorithms, ML has become the linchpin of innovation across various sectors. In the realm of industrial research and development, ML catalyzes a paradigm shift in how industries innovate. At the intersection of advanced data analytics and computational intelligence, ML emerged as an indispensable tool, offering unprecedented capabilities to enhance decision-making, fostering a sustainable and adaptive approach to the evolving landscape of industrial research.
The integration of ML in the domain of steel studies marks a transformative leap in the ability to predict and tailor the properties of steels with unprecedented precision. By harnessing the power of advanced computational algorithms, researchers and industry professionals can delve into vast datasets, extracting intricate patterns that govern the relationships between steel compositions, processing parameters, and alloys’ properties. Therefore, ML can play a powerful role in steel-related studies by enabling advanced data analysis and pattern recognition, opening avenues for predictive modeling, enabling the anticipation of key characteristics, thereby revolutionizing the design, production, and quality control processes in the steel industry [3].
For instance, these algorithms can analyze intricate relationships between input variables and production outcomes, therefore contributing to process optimization. This aids in optimizing manufacturing processes by fine-tuning parameters like temperature, pressure, and steel compositions. Through iterative learning, ML models can adapt to evolving conditions, contributing to enhanced efficiency and resource utilization. In quality control, ML-based systems are adept at detecting anomalies and defects in steel products. Image recognition algorithms, for instance, can scrutinize visual data from production lines, identifying imperfections or irregularities in real-time. This proactive approach reduces waste and ensures the production of high-quality steel. On the other hand, ML can aid in optimizing the steel supply chain by predicting demand fluctuations, identifying potential bottlenecks, and improving inventory management. This ensures a streamlined and responsive supply chain, minimizing delays and optimizing resource allocation [2, 3].
This chapter will be focused on an important application of ML in steel production: Properties Prediction. In other words, it will be explored how ML serves as a dynamic and indispensable tool for forecasting and optimizing the properties of steels for diverse applications. The basics of ML will be introduced and then, examples on how to use ML for cases of material properties will be presented.
2. The basics of machine learning
What exactly is machine learning from its inception? While its definitions may vary slightly across different fields, it can be broadly described as
Machine Learning can be classified according to the kind of learning the system is subjected to, varying from supervised to unsupervised learning, as shown in Figure 1 [2, 4, 5].
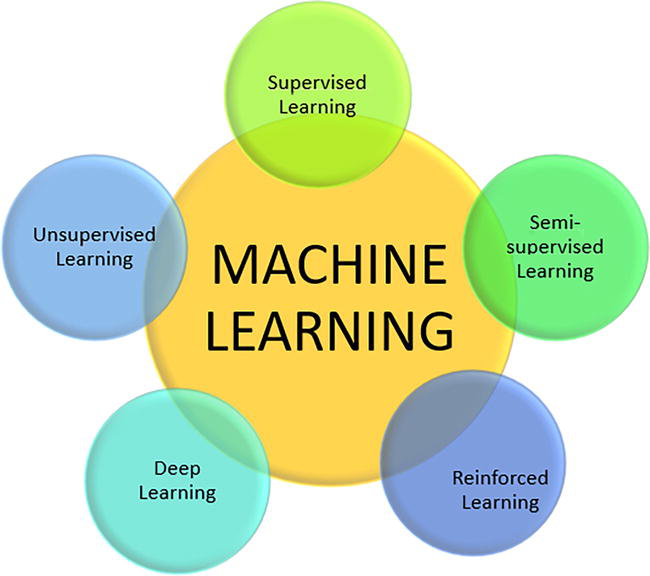
Figure 1.
Classification of machine learning methods.
2.1 Supervised learning
Supervised learning [5] is one of the main categories in machine learning. It involves creating models by using labeled data, also known as instances or examples, in order to learn how to make predictions or decisions. In simpler terms, the model is exposed to a set of input and output examples, where the desired output is provided or labeled for each example. Using these labeled examples, the model learns how to map new inputs to the desired outputs.
This type of algorithm is capable of creating predictive models that estimate a specific property of elements in a set, typically referred to as a target, based on a group of known parameters known as features. To define this model, a process called “training” or “fitting” is necessary. During this process, the algorithm is shown a training set consisting of a large number of examples where the properties of interest are already known. For instance, it is possible to train a model to predict the hardness gain of steels in a certain thermos-mechanical treatment by using a database containing the fractions of alloying elements and instrumental treatment parameters from a wide range of steel compositions. When the target property is a discrete random variable, the model is known as a “classification” model. Conversely, if the target is a continuous random variable, the model is referred to as a “regression” model.
2.2 Unsupervised learning
When working with data that do not have labels, a different algorithm is required. This particular category of models is known as Unsupervised Learning [6], where the algorithm is trained using unlabeled data. The system then attempts to learn patterns, structures, or relationships within the data without any direct guidance or predefined output labels. The objective is to uncover the inherent structure or distribution of the data and uncover hidden patterns or groups. In unsupervised learning, the training dataset only contains input features, with no corresponding output labels to guide the learning process. This includes tasks, such as grouping similar data points together, reducing the complexity of high-dimensional datasets, estimating probability distributions to identify anomalies, discovering association rules, and segmenting data into meaningful groups without any prior knowledge of class labels.
2.3 Semi-supervised learning
Semi-supervised learning [5, 6] is the term used to describe the combination of labeled and unlabeled instances in the training of a learning algorithm. This approach is a middle ground between fully supervised and unsupervised learning models. By utilizing both labeled and unlabeled data, the model can benefit from the guidance provided by the labeled instances while also taking advantage of the larger pool of unlabeled data to improve its ability to generalize. This integration of labeled and unlabeled information is particularly useful in situations where obtaining labeled data is difficult or costly, allowing the model to be applied to real-world scenarios where data scarcity is a challenge. Semi-supervised learning has proven to be valuable in various domains, such as image recognition, natural language processing, and medical diagnostics, where labeled data may be limited, expensive to acquire, or require expert annotation. This makes it ideal for applications where the model’s performance can be enhanced by effectively combining labeled and unlabeled instances.
2.4 Deep learning and reinforced learning
The final two machine learning models, considered to be the most intricate ones, are called Deep Learning [7, 8] and Reinforced Learning [9, 10]. Deep Learning utilizes neural networks that have multiple layers to automatically extract hierarchical representations from data, allowing for the modeling of intricate patterns and features. It has demonstrated exceptional performance in demanding tasks, such as recognizing images and speech, processing natural language, and analyzing sequential data. On the other hand, Reinforcement Learning is a framework in which an agent learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or punishments. This approach is particularly suitable for problems that involve making decisions in a sequence, controlling systems, and optimizing tasks. Deep learning excels in tasks that involve vast amounts of data and complex relationships, while reinforcement learning is well suited for scenarios where an agent must learn optimal strategies through trial-and-error interactions, making it applicable in various fields such as robotics, game playing, and autonomous systems.
3. Determination of steel properties by machine learning
Steel properties (such as physical, chemical, electrical, mechanical, and so on) are mainly acquired in a range of different tests and experiments, by the collection of empirical numerical data, later to be processed and analyzed accordingly [11]. Machine Learning offers, besides other features, an important contribution in terms of data prediction and data analysis never seen before, because it anticipates features that could not be achieved simply by conventional testing. The tremendous computational capability of ML allows the optimization of more intricate steels properties analysis. This section presents a few works that have been developed in the past years, where the use of ML has proven to be an important feature for the determination of some of those steel properties. These examples present cases where distinct types of ML techniques have been used successfully.
3.1 ML on the determination of mechanical properties of steels
Nowadays, many different studies can be found in the literature related to the prediction and determination of mechanical properties of steels. Some of those works are brought here for exemplification of how strong this computational tool can be for the development of steel engineering. Three different studies are presented, depicting how ML became a powerful predictive asset for steel property prediction.
3.1.1 Enhancing manganese (Mn) medium steel’s mechanical properties
Lee et al. [12] created a model dataset of 1075 values acquired from literature related to the tensile properties of manganese medium steels, aiming at the development of a new Mn medium steel with superior high strength. With the analysis of the datasets, authors could create a boosted decision tree regression [BD] model to predict ultimate tensile strength [UTS] and total elongation [TE] of medium-Mn steels. The trained BD models predicted that the Mn medium steel would have high UTS of 1957 MPa and TE of 10.7%, when austenitized at 780°C for 4 min and air-cooled. The predicted UTS and TE matched well with experimentally measured values of UTS of 1952 MPa and TE of 9.9%, indicating the efficacy of the BD models. The steel designed by the BD model exhibited high UTS [1952 MPa] experimentally, which was approximately 100 MPa higher than that of medium-Mn steel.
3.1.2 Steel microstructure modeling
Wang and Adachi [13] developed in their study an important tool based on Machine Learning algorithms, to predict microstructure models where direct analysis of property predictions and properties-to-microstructure inverse analysis was conducted. From those data, they aim to reach steel properties, such as stress–strain curves, tensile strength, and total elongation.
3.1.3 Thermo-mechanically controlled process (TMCP) for steels
Lee et al. [14] used ML to predict how thermo-mechanically controlled process [TMCP] would change some mechanical properties of steel alloys. In their study, the authors gathered 16 attributes related to the compositional and processing information and the corresponding yield strength and ultimate tensile strength values for 5473 thermo-mechanically controlled processed [TMCP] steel alloys. From those data, they designed an ML platform that was able to predict those properties from the chosen attributes.
3.2 ML on the determination of corrosion properties of steels
It is well known that steel degradation and corrosion can generate huge economical and production losses in many industries worldwide. It can also cause catastrophic impacts not only on metallic components and equipment, but also on people’s lives. Therefore, corrosion prevention is mandatory for many processes.
Machine Learning has been a tool for corrosion prevention in many studies. The work of Coelho and colleagues [15] is cited here for its interesting approach. They investigated the pitting corrosion on a 316L steel, which is one of the most utilized steels in the world, due to its good mechanical and corrosion properties. The 316L steel low carbon and high chromium contents enables this material to resist many different types of temperatures and environmental degradation. Their goal was to estimate pitting descriptors for their target steel using scanning electrochemical cell microscopy (SECCM). The methodology mainly consisted of building a hybrid rule-based machine learning approach, via linear regression and artificial neural networks. They were able to observe a trend of passive range shortening with increasing testing aggressiveness due to the delayed stabilization of the passive film, rather than early passivity breakdown.
Aghaaminiha et al. [16] studied how to measure corrosion rates of carbon steel as a function of time when corrosion inhibitors are used in different dosages and dose schedules. Supervised ML was employed and came up with the Random Forest prediction algorithm, among others, because that algorithm displayed the lower mean squared error ranging from 0.005 to 0.093, which are good values for prediction, demonstrating that the entire time trend of the corrosion rate of mild steel was quite well predicted by the trained RF model.
3.3 ML on the determination of microstructural properties of steels
The material microstructure is surely the basic feature of any material from where every property is determined. The specific steel microstructure provides important information on how that steel might behave depending on the external characteristics it might be subject to. Therefore, being able to understand and predict material microstructure is fundamental for steel engineering. Today, one can find many studies on that subject and more and more scientists are employing ML to aid their understanding of steel microstructure.
Kim et al. [17] proposed an ML method using unsupervised deep learning to estimate phase volume fraction of multiphase steel. Their results presented a mean relative error between 0.73% and 4.53%, suggesting that the estimated phase fraction values are very close to the true phase fraction of the multiphase steel.
Kusampudi and Diehl [18] developed an ML model that was able to generate dual-phase steel microstructures, based on the steel phases and crystallographic orientation aiming to build steels with desired properties. Their method consisted of training a variational autoencoder to identify the attributes from a synthetic dual-phase microstructure, with Bayesian optimization. A Rain Forest ML was also employed to predict the microstructure-properties relationship.
3.4 ML on the determination of welding process properties
In the realm of welding research, the utilization of machine learning entails the strategic implementation of computational algorithms as a means of analyzing and optimizing various aspects of the welding process. Machine learning techniques offer the potential to forecast the quality of welds, refine welding parameters to an optimal level, and promptly identify potential flaws or irregularities as they occur.
Through the assimilation of data acquired from sensors, images, and other sources during the welding procedure, machine learning models can acquire an understanding of intricate patterns and correlations, thereby assisting in the construction of predictive models pertaining to weld strength, integrity, and overall quality. Furthermore, the incorporation of machine learning has the capacity to contribute to automated decision-making in welding, such as making real-time adjustments to parameters based on feedback, thereby bolstering efficiency and minimizing the necessity for manual intervention. The integration of machine learning within the domain of welding research holds great promise in advancing the precision, dependability, and productivity of welding processes across a wide array of applications and industries [19].
Tran et al. [20] developed an artificial intelligence-based system to predict several relationships between welding process parameters and weld bead geometries for shielded metal arc welding (SMAW), metal inert gas (MIG), and tungsten inert gas (TIG) processes. The system was built of both a regression model and the deep learning model, establishing a commendable correlation between the welding process parameters and the weld bead geometry. These research findings lay a foundation for constructing predictive systems or refining welding process parameters.
Abd Halim et al. [21] created an application tool called Q-check that utilizes an open-source and customized algorithm based on artificial neural networks to predict parameters such as welding time, current, and electrode force, in relation to tensile shear load-bearing capacity [TSLBC] and weld quality classifications [WQC]. For this purpose, a supervised learning algorithm was implemented, encompassing the standard backpropagation neural network gradient descent [GD], stochastic gradient descent [SGD], and Levenberg-Marquardt [LM] methods, based on an 80% training and 20% test set. The results showed that, for predicting TSLBC, it has achieved an 87.220% accuracy rate for GD, 92.865% for SGD, and 93.670% for LM algorithms. On the other hand, for the prediction of WQC, the accuracy rates were observed to be 62.5% for GD and 75% for both SGD and LM algorithms.
Wang et al. [22] present the design of an intelligent expert system for gas metal arc welding (GMAW) process, with the aim of allowing the user to input the initial welding information, and subsequently display suitable welding procedure parameter schemes through an output interface. The user can then select the most appropriate scheme based on the specific requirements or generate a welding procedure specification in line with the enterprise format for immediate utilization. To do this, the system incorporates database technology and the utilization of the XGBoost machine learning algorithm to further enhance its capabilities. XGBoost is short for eXtreme Gradient Boosting algorithm, which is, in practice, a binary tree based on Gradient Boosting, a supervisioned regression algorithm. By training the model on a dataset, the system can predict the welding raw data and continuously optimize the model by accumulating more data for daily use.
4. Conclusions
This chapter presented an overview on how Machine Learning can be used to predict various steel properties. It could be seen that Machine learning models can analyze various factors, such as chemical composition, heat treatment parameters, and processing conditions, to predict the strength properties of steel, such as yield strength, ultimate tensile strength, and hardness. Machine learning algorithms can also be trained on datasets that contain information about steel composition, environmental conditions, and past instances of corrosion to develop models that can predict the corrosion resistance of different steel grades. Some steel processing features, such as weldability, can also benefit from this technique.
In general, it can be noted that for any type of ML (Supervised, Unsupervised, Semi-Supervised Deep, and Reinforced Learning), the size of the input dataset is crucial for the efficiency of the models to be used in the learning. Datasets with a great amount of data, either from literature or from testing, seem to be fundamental for creating efficient decision trees for more accurate predictions of specific features on materials. That can also aid inverse analysis learning algorithms and promote optimal attribute associations.
By leveraging machine learning techniques, engineers and material scientists can efficiently analyze complex datasets to predict and optimize steel properties for various applications, leading to better material selection and improved performance in real-world scenarios. However, it is important to address the potential challenges and ethical considerations associated with machine learning. It is essential to ensure that the deployment of machine learning technologies aligns with societal values and benefits all individuals.
References
- 1.
Cortes C, Vapnik V. Support-vector networks (PDF). Machine Learning . 1995;20 (3):273-297 - 2.
Kelleher JD, Namee M, D’Arcy A. Fundamentals of Machine Learning for Predictive Data Analytics. Cambridge, MA, USA: The MIT Press; 2015 - 3.
Cheng Y, Wang T, Zhang G, editors. Artificial Intelligence for Materials Science., Springer Series in Materials Science. USA: Springer International Publishing; 2021 - 4.
James G, Witten D, Hastie T, Tibshirani R. An introduction to statistical learning. In: Springer Texts in Statistics. US: Springer; 2021 - 5.
Cerulli G. Fundamentals of Supervised Machine Learning – With Applications in Python, R, and Stata. Cham: Springer; 2023 - 6.
Zhu X, Goldberg AB. Introduction to semi-supervised learning. In: Synthesis Lectures on Artificial Intelligence and Machine Learning. USA: Springer International Publishing; 2009 - 7.
Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge, MA, US: MIT Press; 2016 - 8.
Schmidhuber J. Deep learning in neural networks: An overview. Neural Networks. 2015; 61 :85-117.arXiv :1404.7828 . DOI: 10.1016/j.neunet.2014.09.003 - 9.
Lee D, Seo H, Jung MW. Neural basis of reinforcement learning and decision making. Annual Review of Neuroscience. 2012; 35 (1):287-308. DOI: 10.1146/annurev-neuro-062111-150512 - 10.
Bishop CM. Pattern Recognition and Machine Learning. New York: Springer; 2006 - 11.
ASM Handbook Committee. Properties and Selection: Irons, Steels, and High-Performance Alloys. Vol. 1. USA: ASM Handbook Committee – ASM International; 1990 - 12.
Lee J-Y, Kim M, Lee Y-K. Design of high strength medium-Mn steel using machine learning. Materials Science & Engineering: A, Structural Materials: Properties, Microstructure and Processing. 2022; 843 :143-148 - 13.
Wang Z-L, Adachi Y. Property prediction and properties-to-microstructure inverse analysis of steels by a machine-learning approach. Materials Science and Engineering: A. 2019; 744 :661-670 - 14.
Lee JW, Park C, Do Lee B, et al. A machine-learning-based alloy design platform that enables both forward and inverse predictions for thermo-mechanically controlled processed (TMCP) steel alloys. Scientific Reports. 2021; 11 :11012. DOI: 10.1038/s41598-021-90237-z - 15.
Coelho LB, Torres D, Vangrunderbeek V, et al. Estimating pitting descriptors of 316 L stainless steel by machine learning and statistical analysis. NPJ Materials Degradation. 2023; 7 :82. DOI: 10.1038/s41529-023-00403-z - 16.
Aghaaminiha M, Mehrani R, Colahan M, Brown B, Singer M, Nesic S, et al. Machine learning modeling of time-dependent corrosion rates of carbon steel in presence of corrosion inhibitors. Corrosion Science. 2021; 193 :109904. DOI: 10.1016/j.corsci.2021.109904 - 17.
Kim SW, Kang SH, Kim SJ, et al. Estimating the phase volume fraction of multi-phase steel via unsupervised deep learning. Scientific Reports. 2021; 11 :5902. DOI: 10.1038/s41598-021-85407-y - 18.
Kusampudi N, Diehl M. Inverse design of dual-phase steel microstructures using generative machine learning model and Bayesian optimization. International Journal of Plasticity. 2023; 171 :103776. DOI: 10.1016/j.ijplas.2023.103776 - 19.
Gyasi EA, Handroos H, Kah P. Survey on artificial intelligence [AI] applied in welding: A future scenario of the influence of AI on technological, economic, educational and social changes. Procedia Manufacturing. 2019; 38 :702-714. DOI: 10.1016/j.promfg.2020.01.095 - 20.
Tran N-H, Bui V-H, Hoang V-T. Development of an artificial intelligence-based system for predicting weld bead geometry. Applied Sciences. 2023; 13 (7):4232. DOI: 10.3390/app13074232 - 21.
Abd Halim S, Manurung YHP, Raziq MA, et al. Quality prediction and classification of resistance spot weld using artificial neural network with open-sourced, self-executable and GUI-based application tool Q-Check. Scientific Reports. 2023; 13 :3013 - 22.
Wang X, Chen Q , Sun H, Wang X, Yan H. GMAW welding procedure expert system based on machine learning. Intelligence & Robotics. 2023; 3 (1):56-75. DOI: 10.20517/ir.2023.03